分布式面试题
# **MQ问题**
问题背景
业务场景:秒杀 ——> 下单 ——> 支付
这三个核心流程中,真正并发量大的是秒杀功能,下单和支付功能实际并发量很小。
所以,我们在设计秒杀系统时,有必要把下单和支付功能从秒杀的主流程中拆分出来,
特别是下单功能要做成mq异步处理的。而支付功能,比如支付宝支付,是业务场景本身保证的异步。
## ***1、消息丢失问题***
问题背景:上一步秒杀操作成功了,发送消息的时候出现网络问题或broker挂了等原因,导致消息发送失败,造成消息丢失
解决办法:增加一张消息发送表
具体实现:在生产者发送消息到mq之前,先把这条消息写入消息发送表,消息初始状态是待处理,后在发送mq消息,消费者消费消息时,处理完业务逻辑之后,再回调生产者这个接口,修改消息状态为已处理。
遗留问题:如果生产者已经把消息写入消息发送表了,再发送消息到mq服务端的过程失败了,造成了 消息的丢失,如何处理?
解决办法:使用job,增加重试机制
具体实现:用job,每隔一段时间去查询消息发送表中状态为待处理的数据,然后重新发送mq消息。
遗留问题:那这样是不是也有可能消息被重复消费?
## ***2、消息重复消费问题***
问题背景:如果我们设置了ack机制,当出现网络问题时,ack应答超时,本身就有可能造成消息重复消费,而且我们还设置了job,定时重新发送消息,这样使消息的重复消费的几率大大增加。
解决办法:增加一张消息处理表
具体实现:消费者读到消息之后,先判断一下消息处理表,是否存在该消息,如果存在,表示重复消费,则直接返回。 如果不存在,则进行正常操作,接着将消息写入消息处理表中,再返回。
注意点: 进行正常业务逻辑操作和将消息写入消息处理表中,这个两个操作要放在一个事务当中,保证原子性。
## ***3、垃圾消息问题***
问题背景:上面逻辑看着没啥大问题,但是如果出现消息消费失败的情况。比如:由于某些原因,消 息消费者下单一直失败,一直不能回调状态变更接口,job一直重试,最后导致大量垃圾消息
解决办法:设置发送消息次数
具体实现:每次在job重试的时候,需要判断一下消息发送表中该消息的发送次数是否到达最大限制,如果达到了最大限制,直接返回。如果没有达到,则将次数+1,然后发送消息。这样如果出现异常,也只会产生少量的垃圾消息,不会影响到正常的业务。
## ***4、延时消费问题***
问题背景:用户秒杀成功,下单之后,30分钟之内未进行支付,该订单会被自动取消,回退库存。
实现方法可以用job,但job有个问题,需要每隔一段时间处理一次,实时性不是很好我们还可以用延时队列,rocketMq自带了延时队列的功能
具体实现:下单时消息生产者会生成一张订单,此时的状态为待支付,然后向延时队列中发送一条消息,当到达延时时间,消息消费者读取消息之后,会查询该订单的状态是否为待支付。如 果是待支付状态,则更新订单状态为取消状态。如果不是待支付,说明该订单已经支付过了,则直接返回;
注意点: 用户完成支付之后,会修改订单状态为已支付。
# **分布式事务解决方案**
## **1、两阶段提交(2PC)**

第一个阶段:投票阶段
协调者首先将命令写入日志。
发一个 prepare 命令给 B/C 节点这两个参与者。
B/C 收到消息后,根据自己的实际情况,判断自己的实际情况是否可以提交。
将处理结果记录到日志系统。
将结果返回给协调者。

第二个阶段:决定阶段
当 A 节点收到 B/C 参与者所有的确认消息后;
判断所有协调者是否都可以提交。
如果可以则写入日志并发起 commit 命令;有一个不可以则写入日志并发起 abort 命令。
参与者收到协调者发起的命令,执行命令。
将执行命令及结果写入日志。
返回结果给协调者。
## **2、三阶段提交(3PC)**
相对于 2PC,增加了 CanCommit 阶段和超时机制。如果一段时间内没有收到协调者的 commit 请求,那么就会自动进行 commit,解决了 2PC 单点故障的问题。但是性能问题和不一致问题仍然没有根本解决。
第一阶段:CanCommit 阶段
此阶段所做的事很简单,就是协调者询问事务参与者,是否有能力完成此次事务。如果都返回 yes,则进入第二阶段;有一个返回 no 或等待响应超时,则中断事务,并向所有参与者发送 abort 请求
第二阶段:PreCommit 阶段
此时协调者会向所有的参与者发送 PreCommit 请求,参与者收到后开始执行事务操作,并将 Undo 和 Redo 信息记录到事务日志中。参与者执行完事务操作后(此时属于未提交事务的状态),就会向协调者反馈“Ack”表示已经准备好提交了,并等待协调者的下一步指令。
第三阶段:DoCommit 阶段
在阶段二中如果所有的参与者节点都可以进行 PreCommit 提交,那么协调者就会从“预提交状态”转变为“提交状态”。然后向所有的参与者节点发送 doCommit 请求,参与者节点在收到提交请求后就会各自执行事务提交操作,并向协调者节点反馈 Ack 消息,协调者收到所有参与者的 Ack 消息后完成事务。相反,如果有一个参与者节点未完成 PreCommit 的反馈或者反馈超时,那么协调者都会向所有的参与者节点发送 abort 请求,从而中断事务。
## **3、补偿事务(TCC)**
TCC 其实就是采用的补偿机制,其核心思想是:针对每个操作,都要注册一个与其对应的确认和补偿(撤销)操作。它分为三个阶段:Try、Confirm、Cancel。
Try 阶段主要是对业务系统做检测及资源预留,其主要分为两个阶段。
Confirm 阶段主要是对业务系统做确认提交,Try 阶段执行成功并开始执行 Confirm 阶段时,默认 Confirm 阶段是不会出错的。即:只要 Try 成功,Confirm 一定成功。
Cancel 阶段主要是在业务执行错误,需要回滚的状态下执行的业务取消,预留资源释放。
比如下订单减库存:
执行流程:
Try 阶段:订单系统将当前订单状态设置为支付中,库存系统校验当前剩余库存数量是否大于 1,然后将可用库存数量设置为库存剩余数量 -1:
如果 Try 阶段执行成功,执行 Confirm 阶段,将订单状态修改为支付成功,库存剩余数量修改为可用库存数量。
如果 Try 阶段执行失败,执行 Cancel 阶段,将订单状态修改为支付失败,可用库存数量修改为库存剩余数量。
## **4、柔性事务-可靠消息+最终一致性方案(异步确保型)**
实现:rabbitmq的消息TTL(存活时间)和死信队列Exchange结合

## **5、Seata**
Seata的设计目标是对业务无侵入,因此从业务无侵入的2PC方案着手,在传统2PC的基础上演进。
它把一个分布式事务理解成一个包含了若干分支事务的全局事务。全局事务的职责是协调其下管辖的分支事务达成一致,要么一起成功提交,要么一起失败回滚。此外,通常分支事务本身就是一个关系数据库的本地事务。
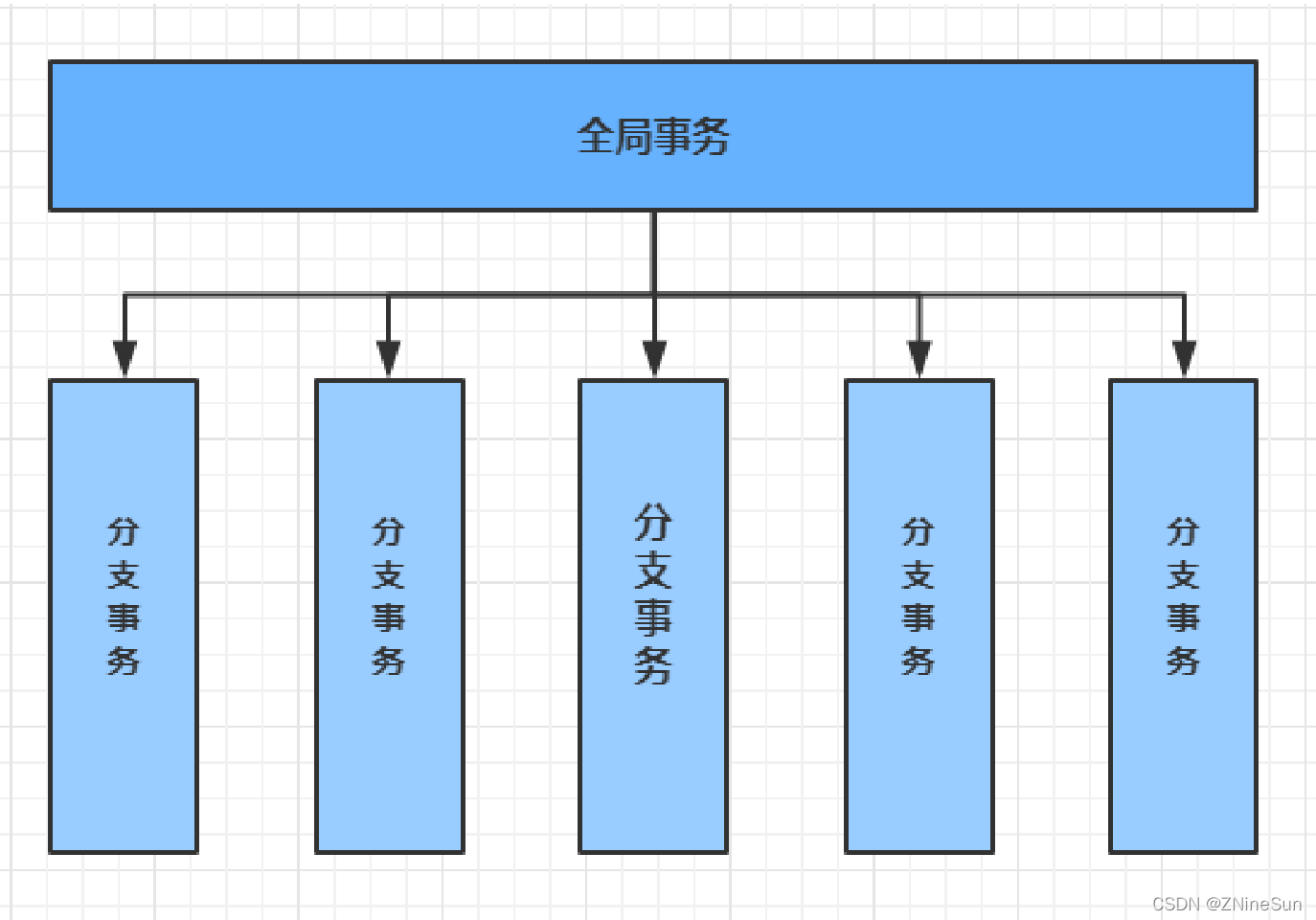
Seata主要由三个重要组件组成:
TC(Transaction Coordinator):事务协调者。管理全局的分支事务的状态,用于全局性事务的提交和回滚。
TM(Transaction Manager):事务管理者。用于开启、提交或回滚事务。
RM(Resource Manager):资源管理器。用于分支事务上的资源管理,向 TC 注册分支事务,上报分支事务的状态,接收 TC 的命令来提交或者回滚分支事务。
5.8.1 AT模式
seata目前支持多种事务模式,分别有AT、TCC、SAGA 和 XA,下面具体讲一讲AT模式
AT模式的特点就是对业务无入侵式,整体机制分二阶段提交(2PC)
一阶段:业务数据和回滚日志记录在同一个本地事务中提交,释放本地锁和连接资源。
二阶段:
1.提交异步化,非常快速地完成
2.回滚通过一阶段的回滚日志进行反向补偿。
在 AT 模式下,用户只需关注自己的业务SQL,用户的业务SQL 作为一阶段,Seata 框架会自动生成事务的二阶段提交和回滚操作。
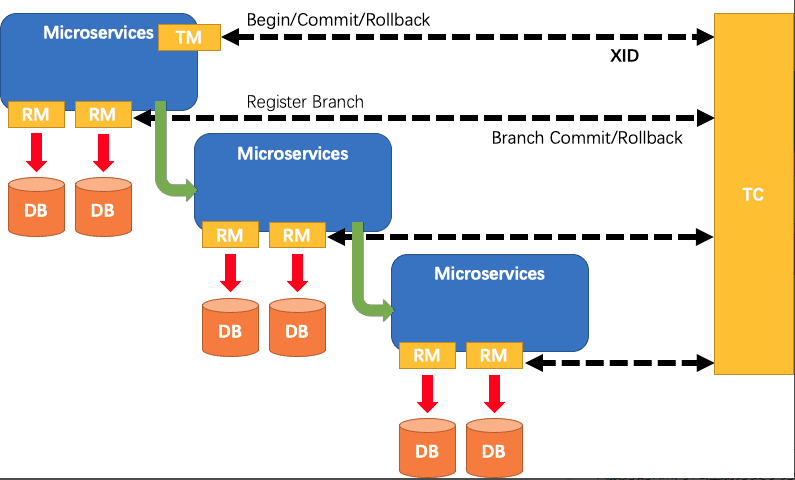
Seata的执行流程如下:
A服务的TM向TC申请开启一个全局事务,TC就会创建一个全局事务并返回一个唯一的XID
A服务的RM向TC注册分支事务,并及其纳入XID对应全局事务的管辖
A服务执行分支事务,向数据库做操作
A服务开始远程调用B服务,此时XID会在微服务的调用链上传播
B服务的RM向TC注册分支事务,并将其纳入XID对应的全局事务的管辖
B服务执行分支事务,向数据库做操作
全局事务调用链处理完毕,TM根据有无异常向TC发起全局事务的提交或者回滚
TC协调其管辖之下的所有分支事务, 决定是否回滚
# **redis集群与DB的数据一致性**
延时双删策略
更新操作时,先删除缓存,再更新数据库,更新完成后,延迟几十到几百毫秒,再删除缓存,保证它的最终一致性。
先删除缓存再更新数据库的问题:如果在数据库更新的时候,有一个请求过来,会重新把数据库的数据写入缓存,这样更新完数据库的话,数据库和缓存的数据就不一致。
先更新数据库再删除缓存的问题:如果更新完数据库,删除缓存失败了,那就无法保证数据一致性。