分类评价指标
# 1、混淆矩阵(Confusion Matrix)
混淆矩阵是ROC曲线绘制的基础,同时它也是衡量分类型模型准确度中最基本,最直观,计算最简单的方法。
**一句话解释版本:**
++混淆矩阵就是分别统计分类模型归错类,归对类的观测值个数,然后把结果放在一个表里展示出来。这个表就是混淆矩阵。++
**混淆矩阵的定义**
混淆矩阵(Confusion Matrix),它的本质远没有它的名字听上去那么拉风。矩阵,可以理解为就是一张表格,混淆矩阵其实就是一张表格而已。
## 1.1 一级指标
以分类模型中最简单的二分类为例,对于这种问题,我们的模型最终需要判断样本的结果是0还是1,或者说是positive还是negative。
我们通过样本的采集,能够直接知道真实情况下,哪些数据结果是positive,哪些结果是negative。同时,我们通过用样本数据跑出分类型模型的结果,也可以知道模型认为这些数据哪些是positive,哪些是negative。
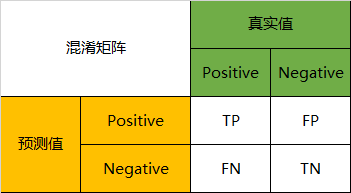
因此,我们就能得到这样四个基础指标,我称他们是**一级指标**(最底层的):
- 真实值是positive,模型认为是positive的数量(True Positive=TP)
- 真实值是positive,模型认为是negative的数量(False Negative=FN):这就是统计学上的**第二类错误**(Type II Error)
- 真实值是negative,模型认为是positive的数量(False Positive=FP):这就是统计学上的**第一类错误**(Type I Error)
- 真实值是negative,模型认为是negative的数量(True Negative=TN)
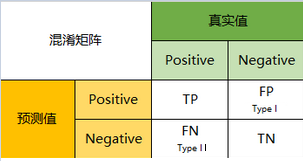
将这四个指标一起呈现在表格中,就能得到如下这样一个矩阵,我们称它为混淆矩阵(Confusion Matrix):
::: hljs-center
:::
**混淆矩阵的指标**
预测性分类模型,肯定是希望越准越好。那么,对应到混淆矩阵中,那肯定是希望TP与TN的数量大,而FP与FN的数量小。所以当我们得到了模型的混淆矩阵后,就需要去看有多少观测值在第二、四象限对应的位置,这里的数值越多越好;反之,在第一、三象限对应位置出现的观测值肯定是越少越好。
## 1.2 二级指标
但是,混淆矩阵里面统计的是个数,有时候面对大量的数据,光凭算个数,很难衡量模型的优劣。因此混淆矩阵在基本的统计结果上又延伸了如下4个指标,我称他们是二级指标(通过最底层指标加减乘除得到的):
- **准确率**(Accuracy)—— 针对整个模型
- **精确率**(Precision)
- **灵敏度**(Sensitivity):就是**召回率**(Recall)
- **特异度**(Specificity)
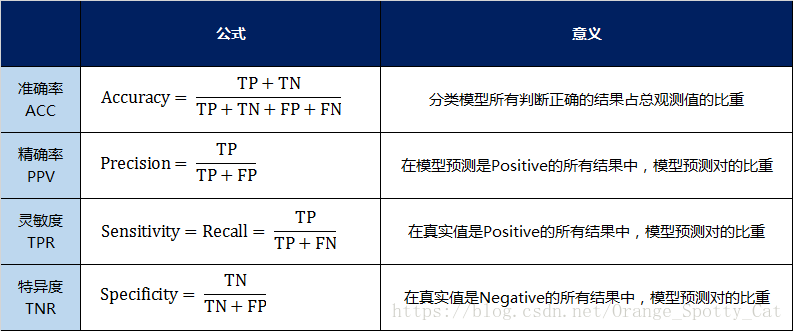
我用表格的方式将这四种指标的定义、计算、理解进行了汇总:
::: hljs-center
:::
通过上面的四个二级指标,可以将混淆矩阵中数量的结果转化为0-1之间的比率。便于进行标准化的衡量。
>**准确率(Accuracy)**
>**局限性**:对于样本类别之间数量差距很大的数据,运用准确率作为评价标准,很容易让模型得到‘满足’(比如我样本里面有99个负例, 1个正例, 那模型预测的时候, 把100个样本都当中负例, 我的准去率是99%, 这样没什么意思啊),但是,我们关注的可能往往是数量较少的呢一个类别,比如免费玩家和充值玩家,对于游戏公司希望对模型对充值玩家的分类性能更好一点。
>
>**解决方案**:针对这种问题,我们可以考虑使用平均准确率(每个类别的样本准确率的算术平均)将其代替
>**精确率与召回率**
>**局限性**:单纯的以精确率为评价标准会导致模型过于‘保守’(一批样本, 比如单独用precisoion的话, 我全部预测为正就好了嘛, 肯定能够预测对一个),不会轻易将样本归类为正样本即划分的阈值设置的很高,导致很多正样本被归为负样本,召回率急剧下降。相反,单纯的以召回率为评价标准也会导致模型过于‘开放’(我多增加一些样本, 比如警察多抓些人, 那肯定抓到小偷的概率就增加了),精确率急剧下降。
>
>**解决方法**:P-R(precision-recall)曲线、F1-score,roc代替
在这四个指标的基础上在进行拓展,会产令另外一个三级指标
## 1.3 三级指标
**F1 Score:**
这个指标叫做**F1 Score**。他的计算公式是:
::: hljs-center
F1 Score $=\frac{2 P R}{P+R}$
:::
其中,P代表Precision,R代表Recall。
F1-Score指标综合了Precision与Recall的产出的结果。F1-Score的取值范围从0到1的,1代表模型的输出最好,0代表模型的输出结果最差。
>**F1 综合了precision和recall的特点**, 对它们做了一个调和,举例: 警察抓小偷, 抓到又多又准
**P-R曲线:**
P-R曲线就是精确率precision vs 召回率recall 曲线,以**recall作为横坐标轴**,**precision作为纵坐标轴**
利用学习器预测结果(样例为正例的概率)对所有样例进行排序,排在前面的是学习器认为最可能是正例的样本。**按照这个顺序逐个将样本选出作为正例进行预测**,则每次可以计算一组召回率和精确率,将召回率作为横轴,精确率作为纵轴,可以绘制得到P-R曲线,如下图所示。
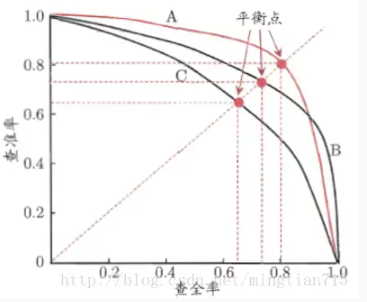
图中曲线是近似处理过的,真实的P-R曲线肯定会过(0,0)点,在一开始,所有样例都判为反例时,TP=0,则P和R均为0;随着逐个将学习器认为是正例概率最大的样例预测为正例,FP接近于0,FN非常的,P会接近1,R会接近0(m足够大);可以预见,逐个将样本预测为正例,被预测为正例的样例逐个增多,R必然单调增大,同时,P会曲折下降;最后,当所有真正例都被预测为正例时,R=1,此时P较小并逐渐接近于 $\frac{m^{+}}{m}$ 。
**P-R曲线模型性能判断规则:**
- 若A曲线包住B曲线(无交叉),则模型A优于模型B;
- 对于曲线有交叉的模型,P-R曲线下面积大者性能更好;
>面积计算复杂,可通过判断平衡点来替代;
>平衡点(P=R处)处值大者性能更好;
## 1.4 混淆矩阵的实例
当分类问题是二分问题时,混淆矩阵可以用上面的方法计算。当分类的结果多于两种的时候,混淆矩阵同时适用。
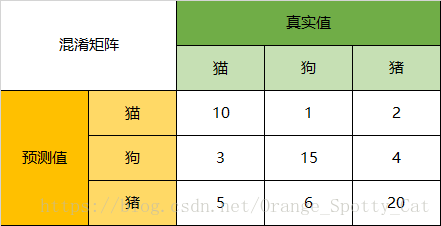
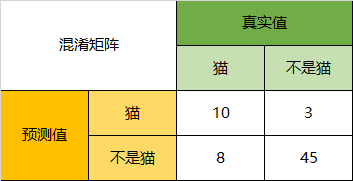
一下面的混淆矩阵为例,我们的模型目的是为了预测样本是什么动物,这是我们的结果:
::: hljs-center
:::
通过混淆矩阵,我们可以得到如下结论:
- ++**Accuracy**++
在总共66个动物中,我们一共预测对了10 + 15 + 20=45个样本,所以准确率(Accuracy)=45/66 = 68.2%。
以猫为例,我们可以将上面的图合并为二分问题:
::: hljs-center
:::
- ++**Precision**++
所以,以猫为例,模型的结果告诉我们,66只动物里有13只是猫,但是其实这13只猫只有10只预测对了。模型认为是猫的13只动物里,有1条狗,两只猪。所以,Precision(猫)= 10/13 = 76.9%
- **++Recall++**
以猫为例,在总共18只真猫中,我们的模型认为里面只有10只是猫,剩下的3只是狗,5只都是猪。这5只八成是橘猫,能理解。所以,Recall(猫)= 10/18 = 55.6%
- **++Specificity++**
以猫为例,在总共48只不是猫的动物中,模型认为有45只不是猫。所以,Specificity(猫)= 45/48 = 93.8%。
虽然在45只动物里,模型依然认为错判了6只狗与4只猫,但是从猫的角度而言,模型的判断是没有错的。
(这里是参见了Wikipedia,Confusion Matrix的解释,https://en.wikipedia.org/wiki/Confusion_matrix)
- **++F1-Score++**
通过公式,可以计算出,对猫而言,F1-Score=(2 * 0.769 * 0.556)/( 0.769 + 0.556) = 64.54%
同样,我们也可以分别计算猪与狗各自的二级指标与三级指标值。
---
转载:[4.4.2分类模型评判指标(一) - 混淆矩阵(Confusion Matrix)](https://blog.csdn.net/Orange_Spotty_Cat/article/details/80520839)
# 2、ROC曲线与AUC面积
ROC曲线与AUC面积均是用来衡量分类型模型准确度的工具。通俗点说,**ROC与AUC是用来回答这样的问题的**:
- 分类模型的预测到底准不准确?
- 我们建出模型的错误率有多大?正确率有多高?
- 两个不同的分类模型中,哪个更好用?哪个更准确?
**一句话概括版本:**
++ROC是一条线,如果我们选择用ROC曲线评判模型的准确性,那么越靠近左上角的ROC曲线,模型的准确度越高,模型越理想;++
++AUC是线下面积,如果我们选择用AUC面积评判模型的准确性,那么模型的AUC面积值越大,模型的准确度越高,模型越理想;++
## 2.1 ROC曲线
ROC曲线全称为受试者工作特征曲线(Receiver Operating Characteristic Curve)。虽然听上去很高端,但是ROC其实非常容易理解。一句话说,ROC就是一张图上的曲线,我们通过曲线的形状来判定模型的好坏。
那么要想了解一个曲线代表什么意思,首先最好搞明白曲线的横轴与纵轴分别代表什么。
::: hljs-center
:::
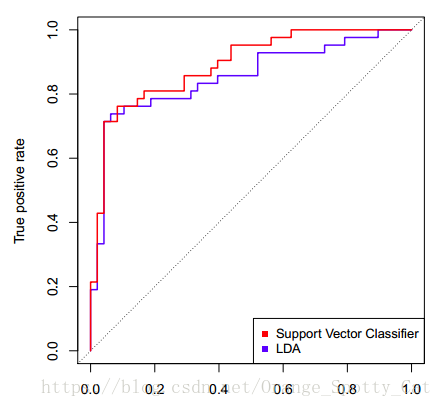
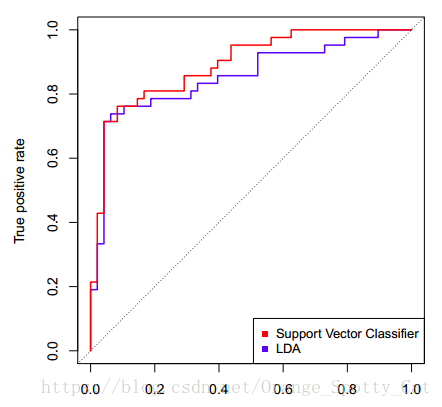
下图中显示的是两条ROC曲线,一条蓝色,一条红色。他们分别对应两个不同的模型。我们可以看到,图中横轴写着“False positive rate”,纵轴写着“True positive rate”。
这两个就是ROC曲线绘制的关键:我们通过计算分类模型的“False positive rate”与“True positive rate”值,分别把它们当成横纵轴,就能够绘制出这个模型的ROC曲线。
那么,怎么计算这两个指标呢?
### 2.11 ROC曲线的计算
ROC曲线的横轴与纵轴,与混淆矩阵(Confusion Matrix)有着密切的关系,具体的理解请详见混淆矩阵篇的讲解。这里只是简单回顾一下:
在分类型模型中,以二分类为例,我们的模型结果一般可以视为0/1问题,或者说positive/negative的问题。模型的产出物,不是positive,就是negative。
我们通过样本的采集,能够直接知道真实的情况下,哪些数据结果是positive,哪些结果是negative。同时,我们通过用样本数据跑出分类型模型的结果,也可以知道模型认为这些数据哪些是positive,哪些是negative。
因此,我们就能得到这样四个结果:
- 真实值是positive,模型认为是positive的数量(True Positive=TP)
- 真实值是positive,模型认为是negative的数量(False Negative=FN)
- 真实值是negative,模型认为是positive的数量(False Positive=FP)
- 真实值是negative,模型认为是negative的数量(True Negative=TN)
将这四种结果一起呈现在表格中,就能得到如下这样一个矩阵,我们称它为混淆矩阵(Confusion Matrix):
::: hljs-center
:::
从名字上就能看出,ROC的横纵轴计算方式是与混淆矩阵有着密切关系的。
**横轴(False positive rate)的计算**:
横轴的指标,在英文中被称为False positive rate,简称FPR。
FPR可以被理解为:在所有真实值为Negative的数据中,被模型错误的判断为Positive的比例。其计算公式为:
::: hljs-center
$\mathrm{FPR}=\frac{\mathrm{FP}}{\mathrm{FP}+\mathrm{TN}}$
:::
**纵轴(True Positive Rate)的计算**:
纵轴的指标,在英文中被称为True Positive Rate,简称TPR。
TPR可以被理解为:在所有真实值为Positive的数据中,被模型正确的判断为Positive的比例。其计算公式为:
::: hljs-center
$\mathrm{TPR}=\frac{\mathrm{TP}}{\mathrm{TP}+\mathrm{FN}}$
:::
### 2.12 ROC曲线的解读
FPR与TPR分别构成了ROC曲线的横纵轴,因此我们知道在ROC曲线中,每一个点都对应着模型的一次结果。
- 如果ROC曲线完全在纵轴上,代表这一点上,x=0,即FPR=0。模型没有把任何negative的数据错误的判为positive,预测完全准确。这是真正的大牛模型,我是做不出来了。
- 如果ROC曲线完全在横轴上,代表这一点上,y=0,即TPR=0。模型没有把任何positive的数据正确的判断为positive,预测完全不准确。平心而论,这种模型能做出来也是蛮牛的,因为模型真正做到了完全不准确,所以只要反着看结果就好了嘛。
- 所以如果ROC曲线完全与右上方45度倾角线重合,证明模型的准确率是正好50%,错判的几率是一半一半。
因此,我们绘制出来ROC曲线的形状,是希望TPR大,而FPR小。因此对应在图上就是曲线尽量往左上角贴近。45度的直线一般被常用作Benchmark,即基准模型,我们的预测分类模型的ROC要能优于45度线,否则我们的预测还不如50/50的猜测来的准确。
所以,回到下图。从整个图上看,红色的ROC线更靠近左上方。因此,红色线代表的SVM分类器的表现要整体优于蓝色线代表的LDA分类器。
::: hljs-center
:::
### 2.13 ROC曲线的绘制
我们已经知道,ROC曲线中的每一个点就能代表一次预测的结果。那么整条ROC的曲线是如何绘制的呢?
答案就是:ROC曲线上的一系列点,代表选取一系列的阈值(threshold)产生的结果。
在分类问题中,我们模型预测的结果不是negative/positive。而是一个negatvie或positive的概率。那么在多大的概率下我们认为观测值应该是negative或positive呢?这个判定的值就是阈值(threshold)。
ROC曲线上众多的点,每个点都对应着一个阈值的情况下模型的表现。多个点连起来就是ROC曲线了。
>**ROC曲线有个很好的特性**:当测试集中的正负样本的分布变化的时候,ROC曲线能够保持不变。在实际的数据集中经常会出现类别不平衡(Class Imbalance)现象,即负样本比正样本多很多(或者相反),而且测试数据中的正负样本的分布也可能随着时间变化,ROC以及AUC可以很好的消除样本类别不平衡对指标结果产生的影响。另一个原因是,ROC和AUC是一种不依赖于阈值(Threshold)的评价指标,在输出为概率分布的分类模型中,如果仅使用准确率、精确率、召回率作为评价指标进行模型对比时,都必须时基于某一个给定阈值的,对于不同的阈值,各模型的Metrics结果也会有所不同,这样就很难得出一个很置信的结果。
## 2.2 AUC面积
AUC的英文叫做Area Under Curve,即曲线下的面积,不能再直白。它就是值ROC曲线下的面积是多大。每一条ROC曲线对应一个AUC值。AUC的取值在0与1之间。
>- **AUC = 1**,代表ROC曲线在纵轴上,预测完全准确。不管Threshold选什么,预测都是100%正确的。
>- **0.5 < AUC < 1**,代表ROC曲线在45度线上方,预测优于50/50的猜测。需要选择合适的阈值后,产出模型。
>- **AUC = 0.5**,代表ROC曲线在45度线上,预测等于50/50的猜测。
>- **0 < AUC < 0.5**,代表ROC曲线在45度线下方,预测不如50/50的猜测。
>- **AUC = 0**,代表ROC曲线在横轴上,预测完全不准确。
>**ROC,AUC:**
>
>**缺点:**
>- ROC,AUC都只适合于二分类
>- AUC只关注正负样本之间的排序,并不关心正样本内部,或者负样本内部的排序。这也体现了AUC的本质:任意个正样本的概率都大于负样本的概率的能力。
>- 线上的排序发生在一个用户的session下,而线下计算全集AUC,即把user1点击的正样本排序高于user2未点击的负样本是没有实际意义的,但线下auc计算的时候考虑了它。
>- ROC曲线的优点是不会随着类别分布的改变而改变,但这在某种程度上也是其缺点。因为负例N增加了很多,而曲线却没变,这等于产生了大量FP。像信息检索中如果主要关心正例的预测准确性的话,这就不可接受了。
>
>**优点:**
>- ROC曲线能很容易的查出任意阈值对学习器的泛化性能影响
有助于选择最佳的阈值。ROC曲线越靠近左上角,模型的查全率就越高。最靠近左上角的ROC曲线上的点是分类错误最少的最好阈值,其假正例和假反例总数最少。
>- 克服样本不平衡
## 2.3 ROC曲线 VS P-R曲线
- ROC曲线由于兼顾正例与负例,所以适用于评估分类器的整体性能,相比而言PR曲线完全聚焦于正例。
- 如果有多份数据且存在不同的类别分布,比如信用卡欺诈问题中每个月正例和负例的比例可能都不相同,这时候如果只想单纯地比较分类器的性能且剔除类别分布改变的影响,则ROC曲线比较适合,因为类别分布改变可能使得PR曲线发生变化时好时坏,这种时候难以进行模型比较;反之,如果想测试不同类别分布下对分类器的性能的影响,则PR曲线比较适合。
- 如果想要评估在相同的类别分布下正例的预测情况,则宜选PR曲线。
- 类别不平衡问题中,ROC曲线通常会给出一个乐观的效果估计,所以大部分时候还是PR曲线更好。
- 最后可以根据具体的应用,在曲线上找到最优的点,得到相对应的precision,recall,f1 score等指标,去调整模型的阈值,从而得到一个符合具体应用的模型。
---
转载:[4.4.2分类模型评判指标(二) - ROC曲线与AUC面积](https://blog.csdn.net/Orange_Spotty_Cat/article/details/80499031)
# 3、KS曲线与KS值
KS曲线是用来衡量分类型模型准确度的工具。KS曲线与ROC曲线非常的类似。其指标的计算方法与混淆矩阵、ROC基本一致。它只是用另一种方式呈现分类模型的准确性。KS值是KS图中两条线之间最大的距离,其能反映出分类器的划分能力。
**一句话概括版本:**
++KS曲线是两条线,其横轴是阈值,纵轴是TPR与FPR。两条曲线之间之间相距最远的地方对应的阈值,就是最能划分模型的阈值。++
++KS值是MAX(TPR - FPR),即两曲线相距最远的距离。++
**KS曲线的定义**
KS曲线与ROC曲线非常相像,了解ROC曲线的人会知道其横轴与纵轴分别是混淆矩阵中的FPR与TPR。而线上的每一个点,都是在不同阈值在得到的FPR与TPR的集合。
如果知道这一事实,那么理解KS就会十分简单。因为KS曲线就是把ROC曲线由原先的一条曲线拆解成了两条曲线。原先ROC的横轴与纵轴都在KS中变成了纵轴,而横轴变成了不同的阈值。
所以总结一下就是:
**++横轴的计算:++**
横轴的指标,是阈值(Threshold)。
分类器的输出一般都为[0,1]之间的概率(Possibilities),那么多少几率我们认为会发生事件,多少几率我们认为不会发生时间。界定“发生”与“不发生”的临界值,就叫做阈值。
比如,我们认为下雨几率高于(含等于)0.7时,天气预报就会显示有雨;而下雨几率低于0.7时,天气预报就不会显示有雨。那么这个0.7,就是阈值。他也是KS曲线的横轴。
**++纵轴的计算:++**
KS曲线中有两条线,这两条线有共同的横轴,但是纵轴分别有两个指标:FPR与TPR。
由于在之前讲过这两个指标,这里就不再赘述。
**KS曲线的解读**
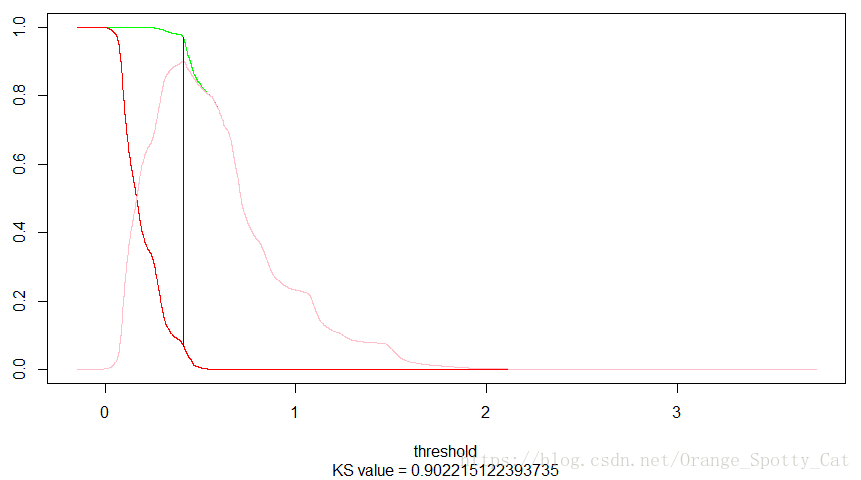
如下图所示,这就是一个典型的KS曲线。
纵轴分别是TPR(绿色线),FPR(红色线)与TPR与FPR的距离(粉色的线)。
横轴我们并未选择传统的阈值(即0-1),我们将横轴变为逻辑回归中预测值Y的概率结果,所以横轴突破了1。在阈值为0.4117361的时候,TPR-FPR的差距是最大的,为0.902215。
因此,我们认为逻辑回归的模型应该将阈值定为41.17%。在这个时候,TPR很高,FPR很低。是最好的输出结果。
::: hljs-center
:::
---
转载:[4.4.2分类模型评判指标(三) - KS曲线与KS值](https://blog.csdn.net/Orange_Spotty_Cat/article/details/82016928)
# 4、多分类
**Macro(宏平均)**: 分别计算每个类的precsion和recall, 再统一平均
**Micro(微平均)**: 先计算总体的TP FP的数量, 对它们平均之后再计算Precision Recall