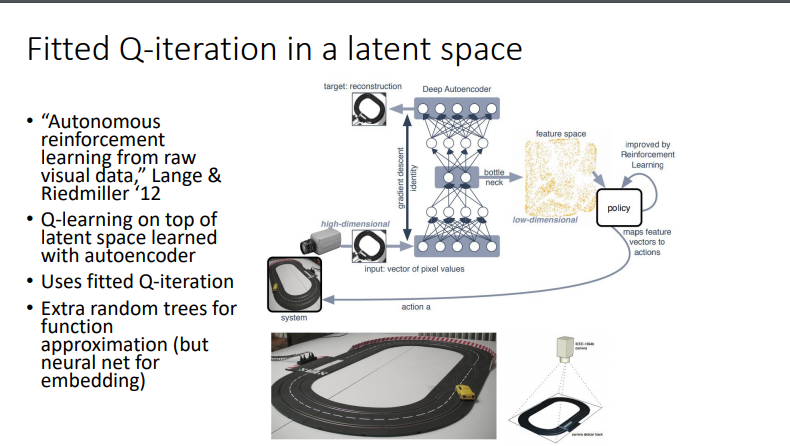
📖 Deep Q-Learning
# Problems of Previous Q-learning
1. correlated samples
2. Q-learning is not gradient descent:
## 1) Correlated samples in Q-learning

### solution: replay buffers

### Full Q-learning with Replay Buffer

## 2) Q-learning is not gradient descent

### solution: target network

### classic Deep Q-Learning Algorithm (DQN)
DQN: Q-learning with neural networks

### Alternative Target Network

# Improve Q-Learning
## Are the Q-values accurate?
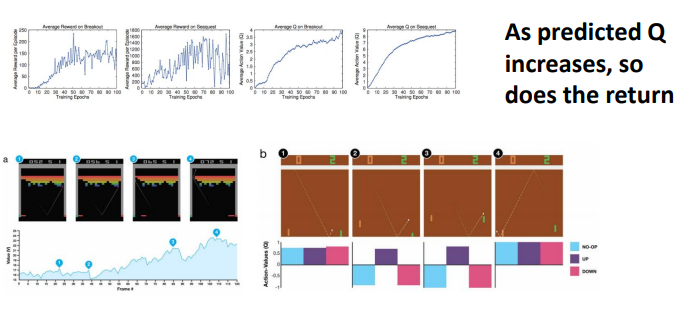
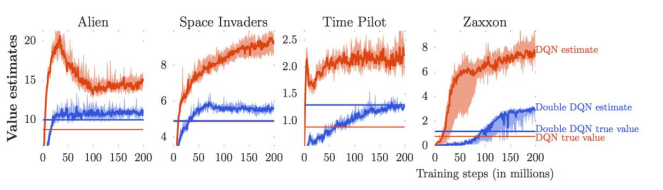
### Overestimation in Q-learning

## 1) Double Q-learning

### Double Q-learning in practice

## 2) Multi-steps returns

### Q-learning with N-steps returns

# Q-learning with continuous actions
What's the problem with continuous actions?
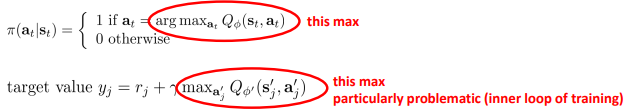
How do we perform the max?
1. Option 1: `optimization`
- gradient based optimization (e.g., SGD) a bit **slow** in the inner loop
- action space typically low-dimensional - what about stochastic optimization?

2. Option 2: `use function class that is easy to optimize`
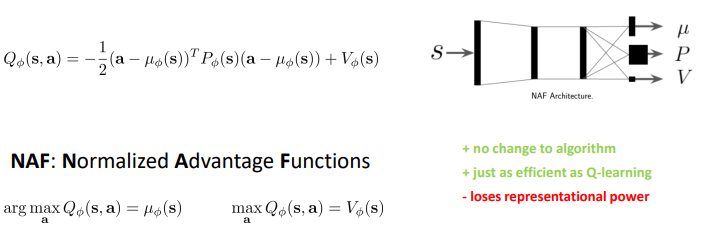
3. Option 3: `learn an approximate maximizer`
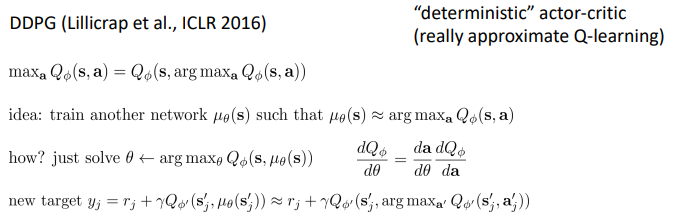

# Implementation Tips and Examples