Cube模块
# 概述
Cube是多为立方体分析的核心,所有的统计计算都是在Cube中定义的,所有预计算的维度也是在cube中详细定义好的。
# 创建Cube
创建Cube也是个流程化的过程,包括选取数据模型(Cube Info)、添加维度(Dimensions)、创建度量(Measures)、数据刷新设置(Refresh Setting)、高级设置(Advanced Setting)、参数配置(Configuration Overwrites),参考如下:

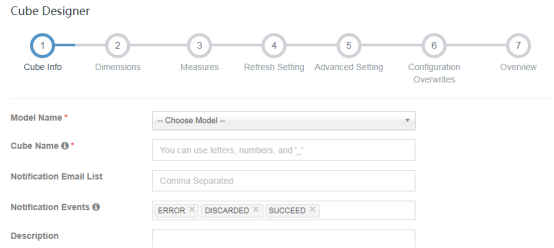
## 选取数据模型
选择所要使用的model(当前project下的),为此cube输入一个唯一的名称(必填),邮件通知列表(选填),用于构建完成或出错时接到通知,如果不想接收某些状态的通知,可以从“Notification Events”中将其去掉,默认有ERROE、DISCARDED、SUCCEED。描述Description(选填)用于添加对Cube的描述信息。
模型(Model Name):必填
Cube名称(Cube Name):必填
通知邮件列表(Notification Email List):选填
通知事件(Notification Events):选填
描述(Description):选填
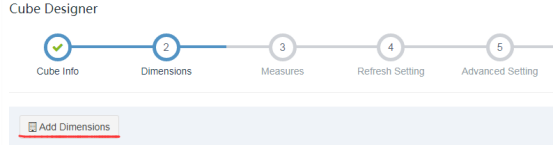
## 添加维度
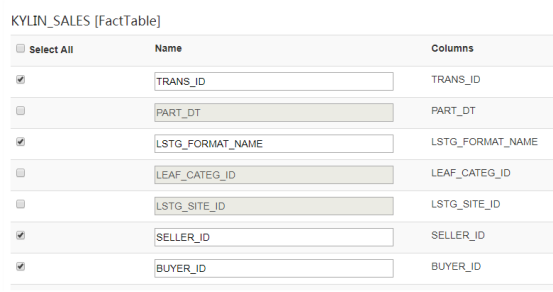
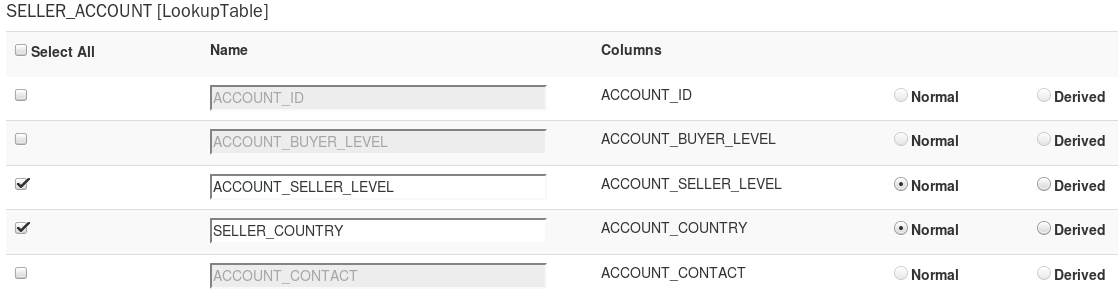
添加Cube的维度,点击按钮添加维度后,会用一个树状结构呈现出所有的列,用户只需要勾选想要的列即可,同时需要为每个维度列输入名字,默认名称为列名,事实表之外的维度表的列可以设定为普通维度或者衍生(Derived)维度。默认为普通维度。
第二步添加维度,参考如下:
事实表:
维度表:
**维度列表展示**
添加完成后能够看到所添加的维度列,参考如下:
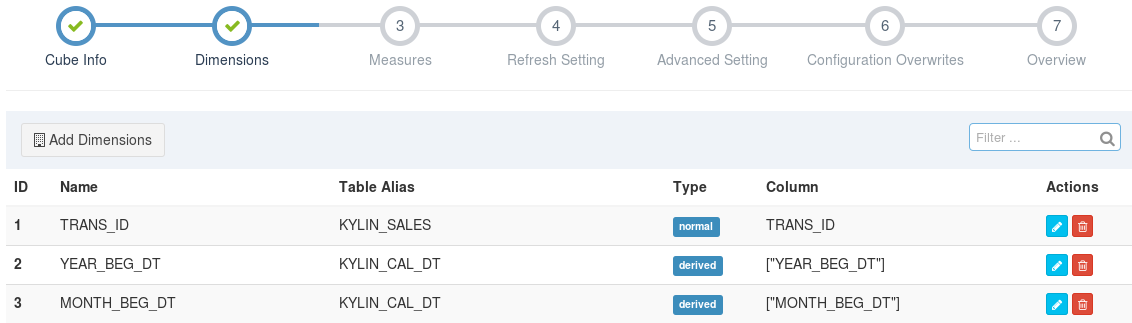
能够对添加的维度进行删除和编辑
**删除**
在该步骤中,对添加完成后的维度列可以进行删除
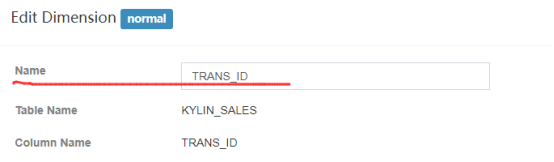
**编辑**
此处编辑只能编辑维度的名称,参考如下:
## 创建度量
在此步骤中,主要是创建多个度量计算,且以列表的形式展示已经创建的度量。
支持的度量有SUM、MIN、MAX、COUNT、COUNT_DISTINCT、TOP_N、EXTENDED_COLUMN、PERCENTILE等,默认会创建一个Count(1)度量。参考如下:
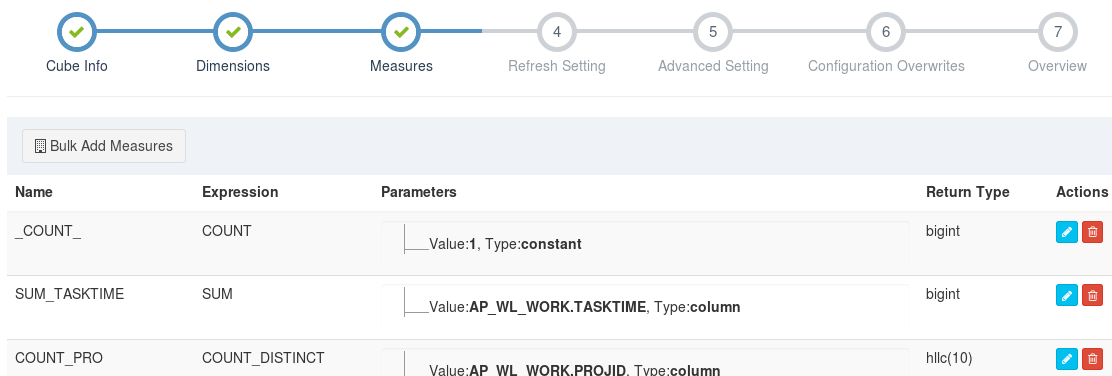
**添加度量**
**SUM、MIN、MAX、COUNT**
添加页面参考如下:
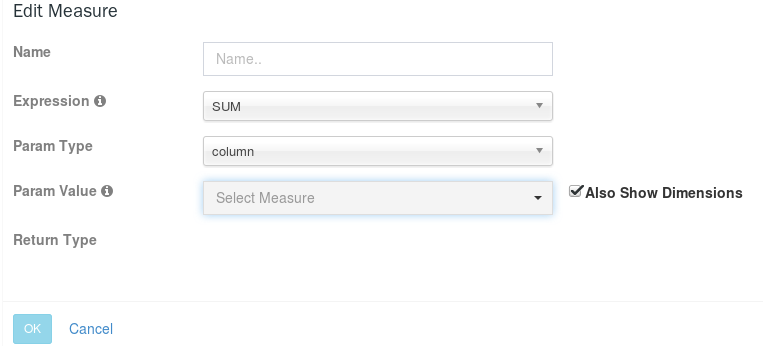
名称(Name):该度量的名称,必须
度量方式(Expression):有SUM、MIN、MAX、COUNT、COUNT_DISTINCT、TOP_N、EXTENDED_COLUMN、PERCENTILE,默认为SUM。
参数类型(Param Type):有列(column)和常数(constant)
参数值(Param Value):如果参数类型是列,那么此处展示出所有的度量列(model中所选择的度量)和维度列(上一步中所选择的维度列),默认只展示度量列,可以选择展示维度列。如果参数类型是常数,那么此为值为1,且不可更改。
返回类型(Return Type):
SUM:如果选择的列类型为整数(int、bigint),那么返回值为bigint;如果返回值为浮点数(float、double),那么返回值为decimal(19,4);如果返回值为字符串(string),那么返回值为VARCHAR(256)。
MAX和MIN:返回值类型和所选择列的类型一致。
COUNT:返回值类型为BIGINT。
**COUNT_DISTINCT**
添加参考页面如下:
COUNT_DISTINCT可以选择多个列:
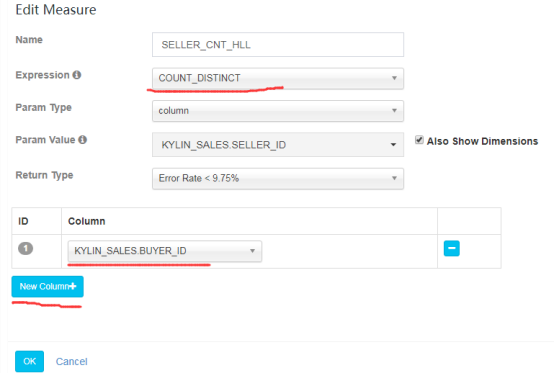
该度量后台有两种实现方式:
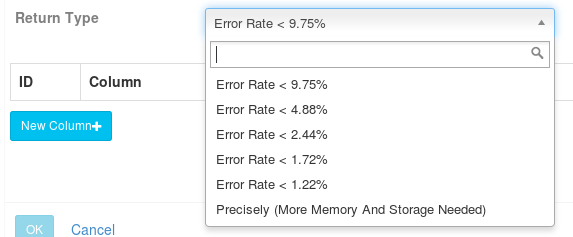
1)近似实现 HyperLogLog,选择可接受的错误率,低错误率需要更多存储;提供了错误率 <9.75%、<4.88%、<2.44%、<1.72%、<1.22%几种精度供选择.用在需要快速计算、节省存储空间,并且能接受错误率的Count Distinct指标计算
2)精确实现 bitmap,需要很大内存和较长计算时间。如果数据中的不重复值超过百万,结果所占的存储应该会达到几百MB。
返回值类型(Return Type),参考如下:
TOP_N
TopN 度量在每个维度结合时预计算,它比未预计算的在查询时间上性能更好;需要两个参数:一是被用来作为 Top 记录的度量列,Kylin 将计算它的 SUM 值并做倒序排列;二是 literal ID,代表最 Top 的记录,例如 seller_id。
添加参考页面如下:
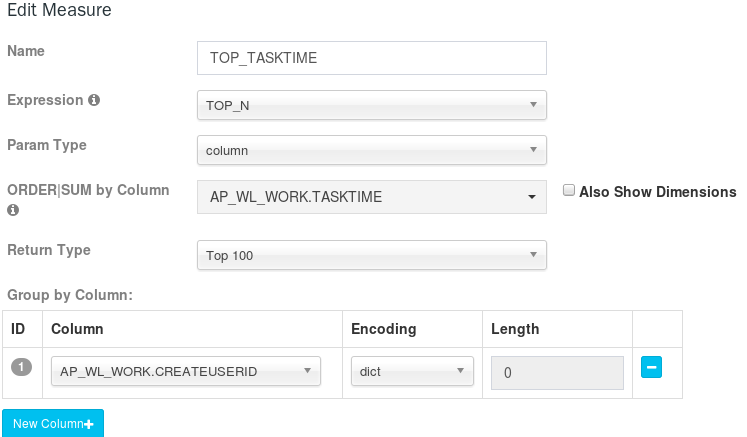
需要为 “ORDER | SUM by Column” 添加一个 SUM 度量。例如,如果您创建了一个根据价格的总和选出 top100 的卖家的度量,那么也应该创建一个 SUM(price) 度量
在完成Top N的添加完成后,度量列表上展示的Top度量参考如下:

## 数据刷新设置 ==该功能当前可以不考虑,参数可以恒定为默认值==
这一步骤是为增量构建 cube 而设计的。
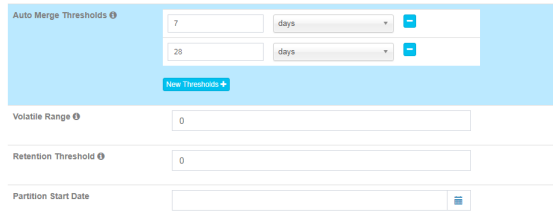
Auto Merge Thresholds: 自动合并小的 segments 到中等甚至更大的 segment。如果不想自动合并,删除默认2个选项。
Volatile Range: 默认为0,会自动合并所有可能的 cube segments,或者用 ‘Auto Merge’ 将不会合并最新的 [Volatile Range] 天的 cube segments。
Retention Threshold: 只会保存 cube 过去几天的 segment,旧的 segment 将会自动从头部删除;0表示不启用这个功能。
Partition Start Date: cube 的开始日期.
## 高级设置 ==该功能相当复杂,需要再商定==
在此页面可以设置维度聚合组和Rowkey属性,属于高级调优及设置,但又必不可少。
可分为聚合组(Aggregation Group)、行健(Rowkeys)、组合白名单(Mandatory Cuboids)、计算引擎(Cube Engine)、字典构建(Advanced Dictionaries)、全局维表(Advanced Snapshot)、度量分组(Advanced Column Family)这七大部分。
**一、聚合组(Aggregation Group)**
默认会把所有**普通维度**放在同一个聚合组中,在单个聚合组中,可以对维度设置一些高级属性,如强制维度(Mandatory Dimensions)、层级维度(Hierarchy Dimensions)、联合维度(Joint Dimensions)。
**强制维度**:指的哪些总是会出现在where条件或Group By语句里的维度。通过指定某个维度为强制维度,那么系统可以不计算那么不包含此维度的Cuboid(排列组合),从而减少计算量。
**层级维度**:是指一组有层级关系的维度。例如 “国家” -> “省” -> “市” 是一个层级;“国家”是高级别维度,“省”、“市”依次是低级别维度,用户会按照高级别维度进行查询,也会按低级别维度进行查询,但是当查询低级别维度时,往往会带上高级别维度的条件,而不会孤立的使用低级别维度。例如,用户会使用“国家”作为维度查询数据,也会使用“国家”+“省”,或者“国家”+“省“+”市”作为维度进行查询,但不会跨越“国家”直接使用“省”、“市”作为维度查询数据。 定义层级维度时,将父级别维度放在子维度的左边。通过指定层级维度,系统可以略过不满足此模式的Cuboid
**联合维度**:是将多个维度看做一个维度,在进行组合计算时,要么一起出现,要么不出现。总是一起查询的维度或者彼此间有一定映射关系的维度。
参考如下图:
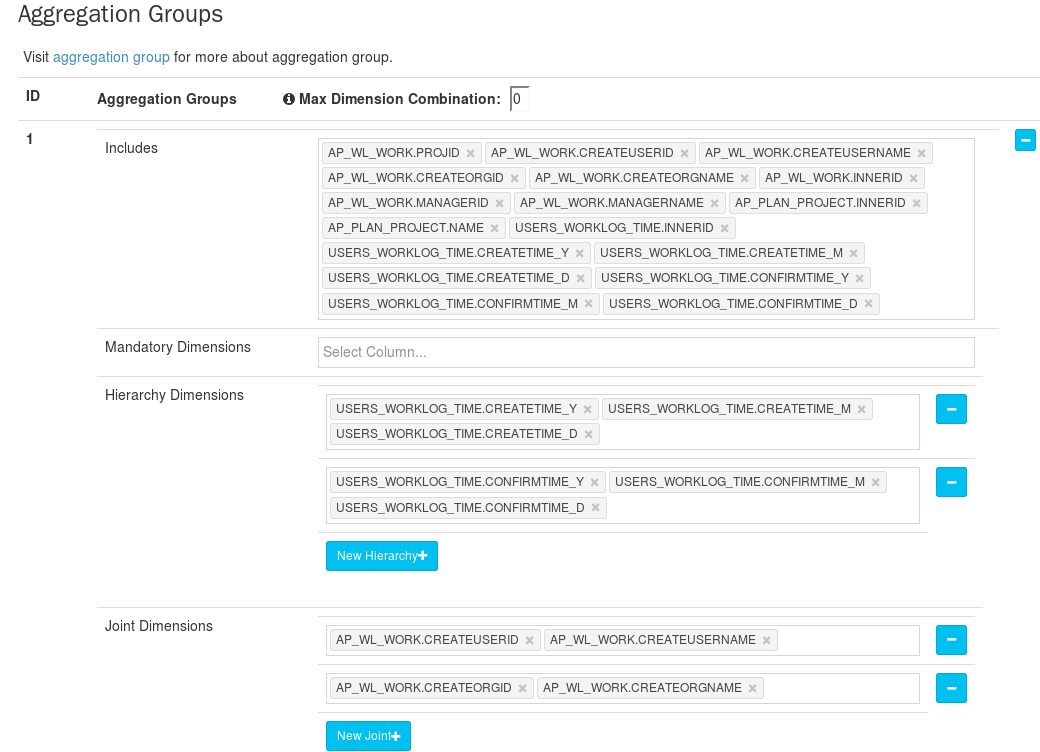
先通过在“Includes”中选择要添加的维度到本聚合组中,然后根据模型特征和查询模式,设置高级维度属性。层级维度和联合维度可以设置多组,但是一个维度出现在某个高级属性中后,将不能再设置为另一种属性。不过一个维度可以出现在多个聚合组中。默认是一个聚合组,==当前研发阶段,就设为一个聚合组==
**二、行健(Rowkeys)** ==初始版本可后端设为默认值==
Cube的构建结果数据是按照key-value的形式存储到HBase中的。HBase的Rowkey(行健)是用来检索数据的唯一索引。
参考如下:
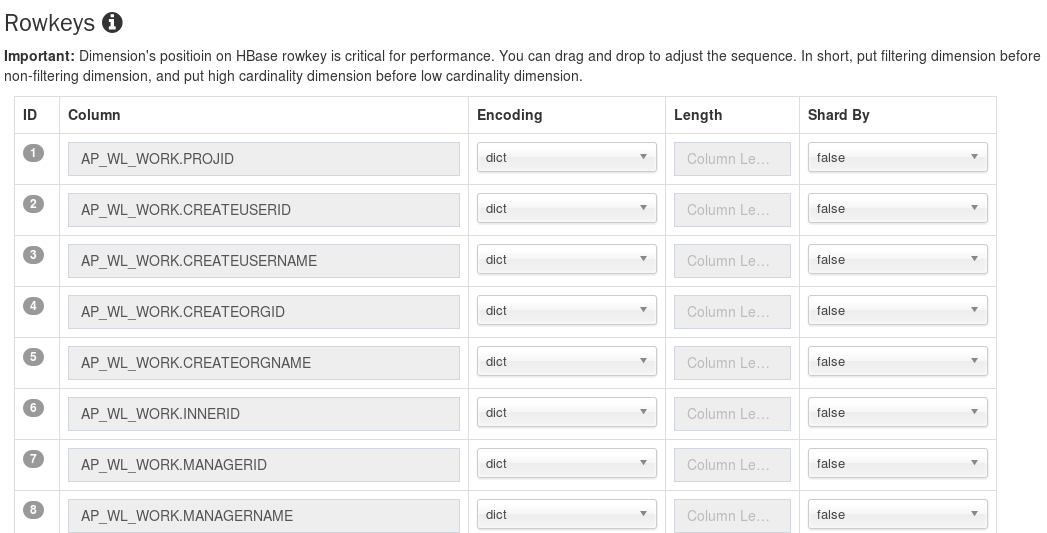
ID是该列在行健中的顺序,Column是所有的维度列,Encoding是该维度值的编码方式,默认采用字典(dict),有dict、data、time、integer、boolean、fixed_length。Length是编码长度,dict没有长度值。Shard By 是宽表数据重新分配,避免数据倾斜的一种调优策略,默认设为false。
**三、组合白名单(Mandatory Cuboids)** ==初始版本可后端设置默认空值==
可以将常用的明确查询的维度加入白名单,确保常用查询维度组合cuboid一定会被预计算。默认为空
**四、计算引擎(Cube Engine)**
有两种选择,MapReduce和Spark
**五、字典构建(Advanced Dictionaries)** ==初始版本可后端设置默认空值==
对复杂的COUNT DISTINCT度量进行字典构建,以保证查询性能,提供两种字典格式:Global Dictionary和Segment Dictionary
**六、全局维表(Advanced Snapshot)** ==初始版本可后端设置默认空值==
将某张维表加载进内存,设为全局维表,默认为空
**七、度量分组(Advanced Column Family)**
对度量进行分组。当有超过一个COUNT DISTINCT 或Top N 时,将它们放在更多的列族中,以优化与HBase的I/O。默认会将SUM、Max、MIN、COUNT放在一个组,将COUNT DISTINCT 和Top N放在另一个组中。
## 参数重配置 ==初始版本可后端设置默认空值==
为Kylin的各个参数根据环境进行重新配置,参考如下:
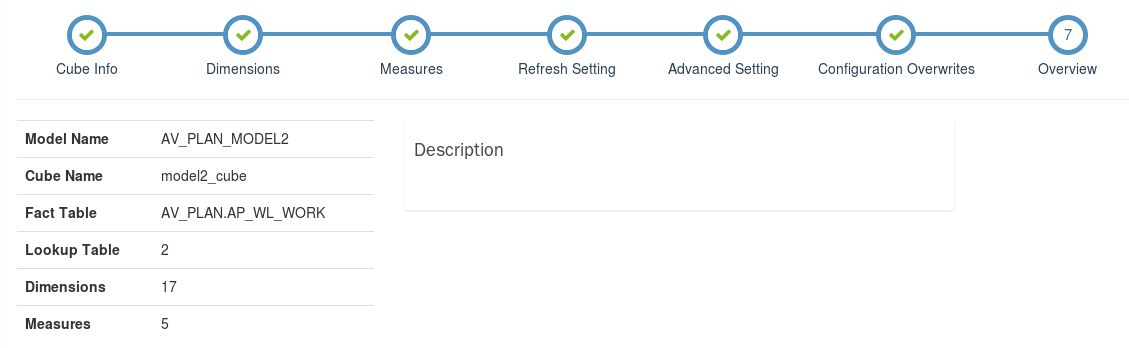
## 概况
从整体上描述本次创建的Cube:模型名称(Model Name)、Cube名称(Cube Name)、事实表(Fact Table)、观察表数量(Lookup Table)、维度数(Dimensions)、度量方法(Measures)、描述(Description)。参考如下:
# 列表展示
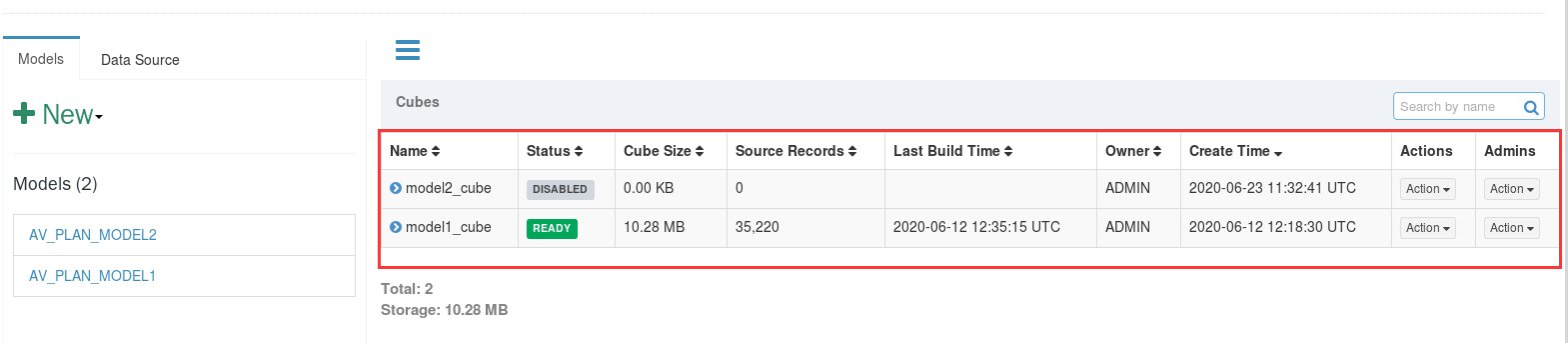
Cube创建完成后,会在Cube列表中进行展示,展示信息有:名称(Name)、状态(Status)、Cube大小(Cube Size)、记录数(Source Records)、最新构建时间(Last Build Time)、创建者(Owner)、创建时间(Create time)、操作(Actions)、编辑查看(Admins)。参考如下图:
# 操作
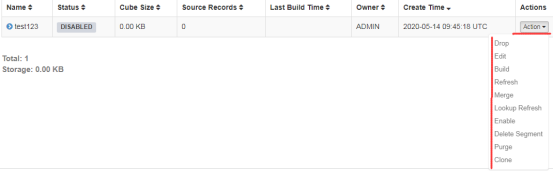
点击Action,下拉框中会出现所有的操作,包括丢弃(Drop)、编辑(Edit)、构建(Build)、Merge(合并)、Lookup Refresh(维表存储更新)、Enable、Delete Segment、Purge、克隆(Clone)。
cube在被构建之前(处于DISABLE状态)的操作有丢弃(Drop)、编辑(Edit)、构建(Build)、Refresh、Merge(合并)、Lookup Refresh(维表存储更新)、Enable、Delete Segment、清除(Purge)、克隆(Clone)。
cube被构建后(处于READY状态)的操作有丢弃(Drop)、编辑(Edit)、构建(Build)、Refresh、Merge(合并)、Lookup Refresh(维表存储更新)、停用(Disable)、克隆(Clone)
**构建(Build)**
点击构建、确定后,调用Cube下的构建Cube函数,进行预计算。
**编辑(Edit)**
点击Edit,出现Cube的整个流程构建步骤,参考如下:
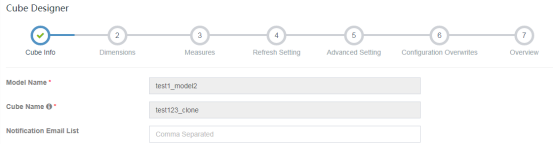
除了Model Name、Cube Name不可更改外,剩余流程步骤中的所有信息均可更改。
**克隆(clone)**
克隆一份和当前Cube结构一样的新cube。
**删除(Drop)**
删除该cube信息
**清除(purge)**
清除已经构建好的cube的数据,清楚后的cube如果要被使用,必须重新被构建build。
**Enable**
Cube未被构建时,是处于Disable状态的,因为未被构建,所以点击Enable是无效的。
如果该Cube是已经被构建完成,然后又操作了Disable,是可以转为点击Enable转为READY状态的
**Disable**
将处于Ready状态的cube置为disable状态,是该cube不可用。
**Refreash** 初始版本忽略
包含有处于有Hive分区字段的Cube才能执行。
**Merge** 初始版本忽略
包含有处于有Hive分区字段的Cube才能执行。
**Lookup Refresh** ==初始版本忽略==
涉及HBase segment的刷新