模型模块
# 概述
创建工程后会自动跳转到模型(Model)页面。
参考如下:
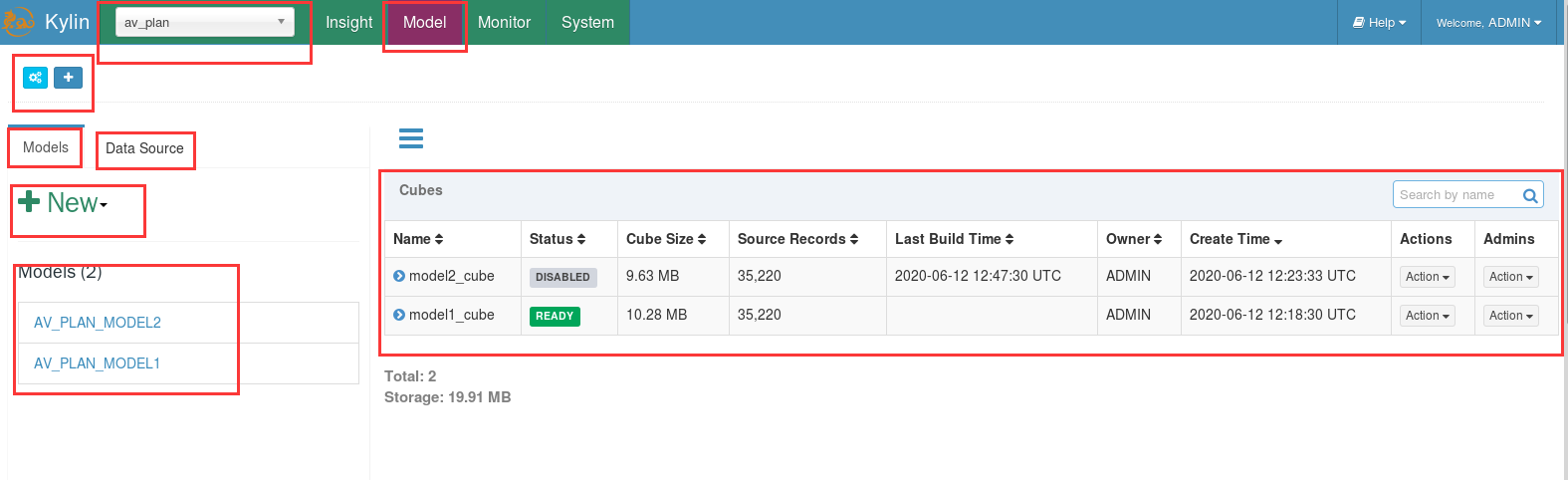
有了表信息后,就可以创建数据模型了。数据模型(Data Model)是Cube的基础,主要是根据需求分析进行设计,可以看做是一个设计简易数据仓库的过程,是为了生成星型模型、雪花模型这类数据模型。主要功能是从加载的数据表中选择维度和度量、构建表连接(靠主外键建立表与表之间的联系)及设置。此外,整个model的构建是一个流程化的步骤。Model创建完成之后,对model可以做一些详细信息查看、编辑、删除、克隆等操作
# 创建模型
按照流程时间线,分为模型信息(Model Info)、数据模型(Data Model)、维度(Dimensions)、度量(Measures)、设置(Setting),页面参考如下:
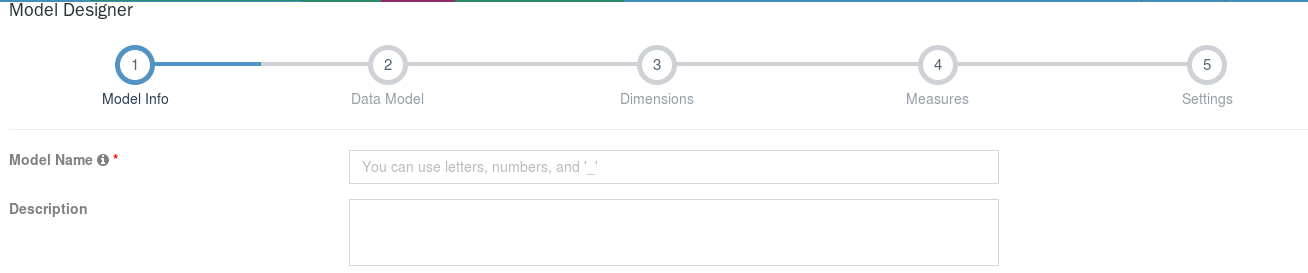
## 模型信息
主要是填写模型的名称,以及对模型的一些描述性信息(非必须)

## 数据模型
该步骤主要功能是从数据源已经加载的数据表中,添加事实表和维度表。参考页面:
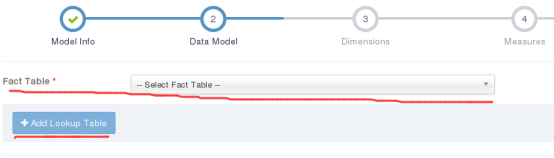
**事实表**
以下拉框或者其他形式展现出所有加载的数据表,可以选中某一表作为事实表
**维度表**
添加维度表的时候,首先选择表之间的连接关系(有inner join和left join两种关系),并为创建的维度表输入别名。同时可以选择是否将其以快照形式存储到内存中以供查询,默认不选中。然后选择连接的主键和外键,支持多主键。
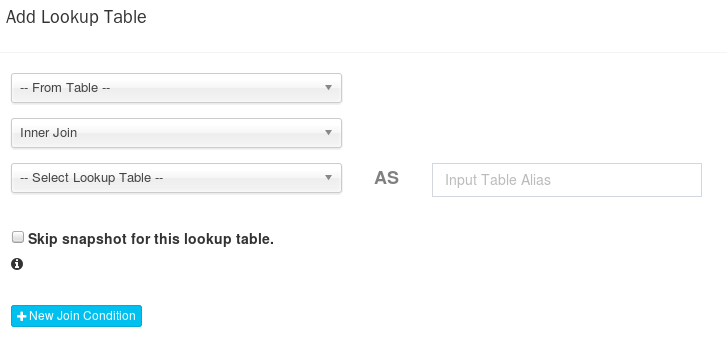
From Table下拉框中是事实表和上一步新生成的观察表(维度表),即每添加一次观察表完成后,下一次再次添加观察表时,上一次添加的观察表别名都会在该下拉框中出现。
Inner Join 下拉框中是事实表和维度表的连接方式:Inner Join 和Left Join,默认为Inner Join
Select Lookup Table下拉框中是列出该project下的所有表,并为创建的维度表输入别名(只能大写字母和数字)。同时可以选择是否将其以快照(Snapshot)形式存储到内存中以供查询。当维度表小于300M时,推荐启用以快照形式存储,以简化Cube计算和提高系统整体效率;当维度表大于300M时,建议关闭快照形式存储(即不打对号),以提升Cube构建的稳定性与查询的性能。然后选择连接的主键和外键,这里支持多主键。
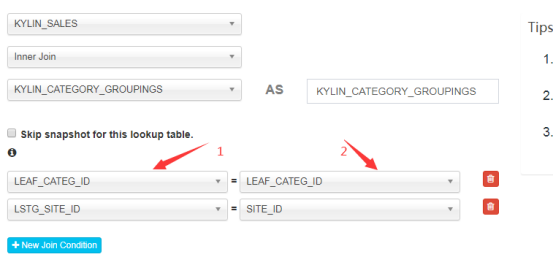
1是事实表的外键,2是维度表的主键
==注==:别名非常重要,例如:数据源中的有一个维度表A,在此处可以通过别名形成新的维度表A1和A2,A1、A2、A中的所有列均相同,在下一步的维度选择中选择不同的列作为维度,这样就能将一张宽维度表分解成一个个主题明确的窄维度表。
## 维度选择
选择维度列时,纬度可以来自事实表或者维度表。这里只是选择一个范围,不代表这些列将来一定会用到,只是把所有可能用到的都选出来。
所有的维度均来自与上一步添加的事实表和维度表。参考界面如下:

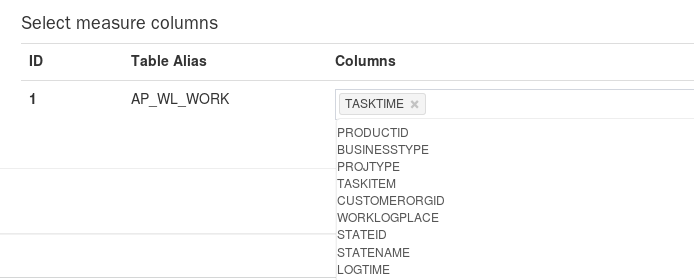
## 度量选择
度量列只能来自事实表或不加载进内存的维度表(即上一步没有生成snapshot的维表)。参考页面:
## 设置 ==该功能当前可以不考虑==
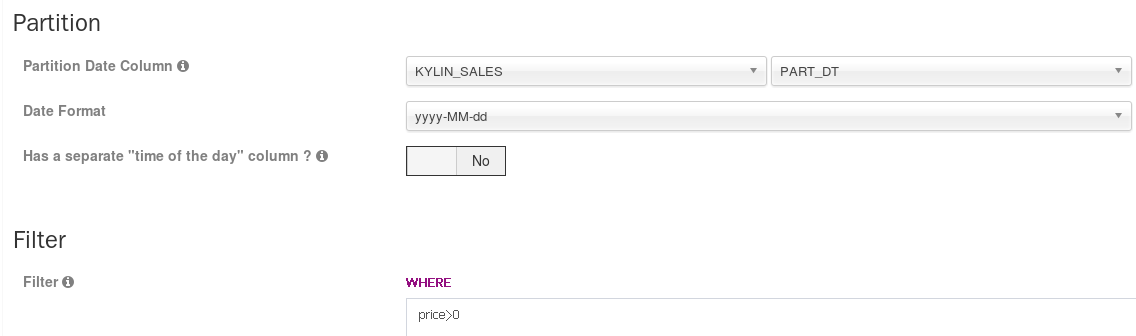
设置是为模型补充分割时间列信息和过滤条件。
如果此模型中的事实表记录是按时间增长的,那么可以指定一个日期/时间列作为模型的分割时间列,从而可以让Cube按此列做增量构建。
过滤(Filter)是指如果想要把一些纪律忽略掉,那么可以设置一个过滤条件
最后,保存此数据模型,随后它将出现在“模型列表”中。
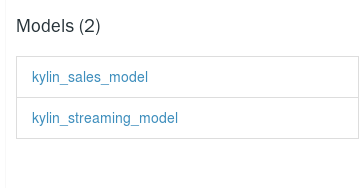
# 模型列表
用于列出当前工程Project下的所有数据模型model,参考如下:
# 操作模型
主要是对“模型列表”中的模型进行模型信息查看、编辑模型、删除模型、克隆模型等操作。
## 模型信息查看
在模型列表中,点击某个model,会跳出一个页面用于模型信息的详细展示,有三种展示方式:流程节点展示(Grid)、模型可视化(Visualization)、JSON。
**流程节点展示**
以流程化创建模型的步骤进行每个节点步骤的信息展示,参考如下:
**模型可视化** ==该功能当前阶段可以不用考虑==
以表节点关系图的形式,可视化的整体描述当前模型,参考如下:

所有数据表以主外键连接关系绘制成一张图表。
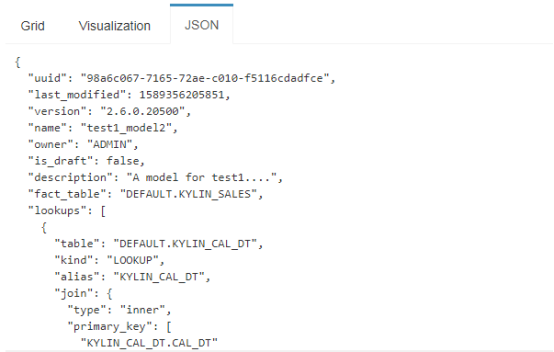
**JSON**
将整个模型信息进行JSON字符串化,详细展示其构造信息。参考如下:
## 编辑模型
点击“编辑”,如果此模型没有被cube使用(可以根据API的返回信息判断),进入模型的编辑流程,编辑流程和模型构建流程一致。参考如下:

编辑结束后,保存模型,返回“模型列表”
## 删除模型
点击“删除”后,如果此模型没有被cube使用(可以根据API的返回信息判断),可以确认删除此模型。最后返回“模型列表”
## 克隆模型
用于克隆复制某一模型,点击克隆后,弹出页面,更改模型名称,提交后复制此模型,返回“模型列表”