数据源模块
创建完工程(Project)后,要为该project添加数据源。
数据源只支持Hive,无需手动配置,在整个Hadoop生态集群(至少包含mapreduce、yarn、Hive、HBase、Zookeeper、kylin)启动后,kylin会自动关联到当前生态环境中的Hive。
这里所说的数据源是指在连接到数仓Hive的前提下,去选择Hive中的数据库及库中的相关表。
## 添加数据表
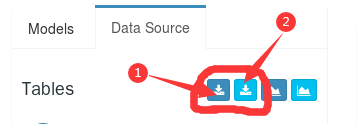
数据表的添加有两种方式:
**方式一**:直接填写所需的数据库及数据表,参考如下:
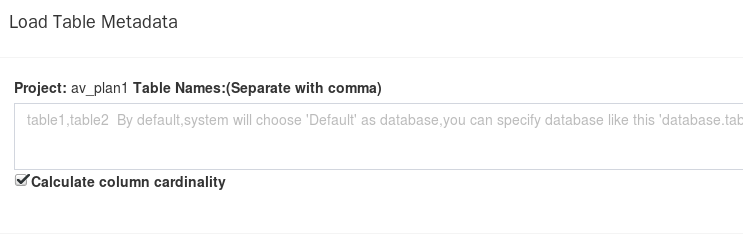
直接在输入框中填入所要加载的数据表,格式为:db1.table1,db1.table2,db1.table3,
以英文逗号结尾。
计算列基数(Calculate column cadinality),默认是为真,添加计算。
**方式二**:直接从数据库树状图上进行选择,参考如下:

主要是分为三部分:
1. 列出当前Hive下的所有数据库
2. 点击数据库,展开列出其下的所有表
3. 填写数据表的过滤条件
## 列表
用于列出当前project的数据表及其相关信息。
参考如下:
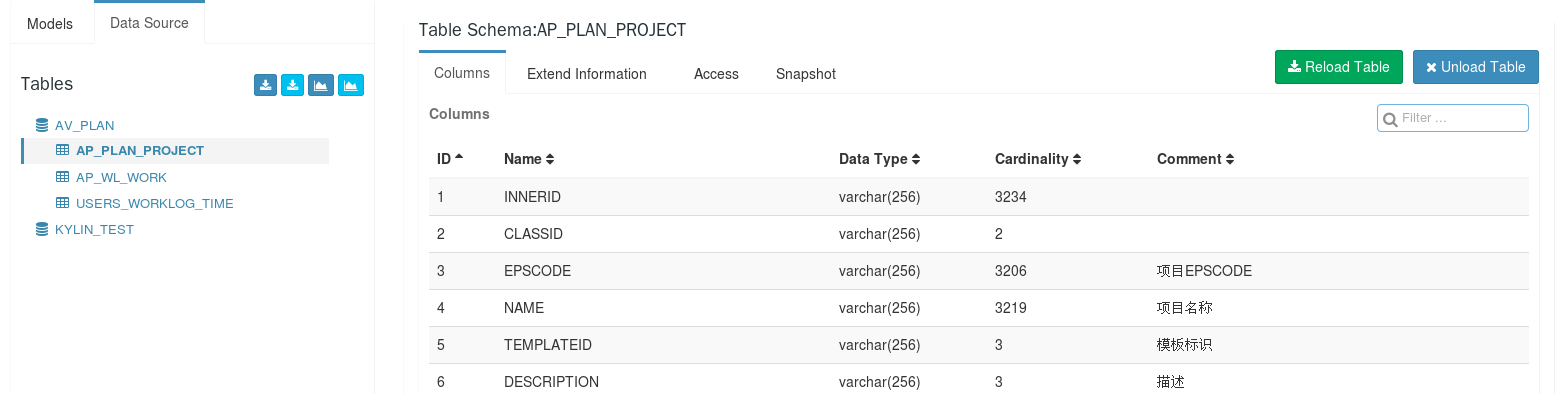
### Tables展示
以结构树的形式展示当前所有的数据表,
父节点为数据库,可以有多个;
子节点为该库下添加的数据表,不是原数据库下的所有数据表,而是添加数据表时所选择添加的数据表;
孙节点为当前表下的所有数据列,==该节点可以不用展示==
### 表信息
当点击左侧树结构下的某个数据库下的数据表时,右侧呈现出当前表的详细信息。
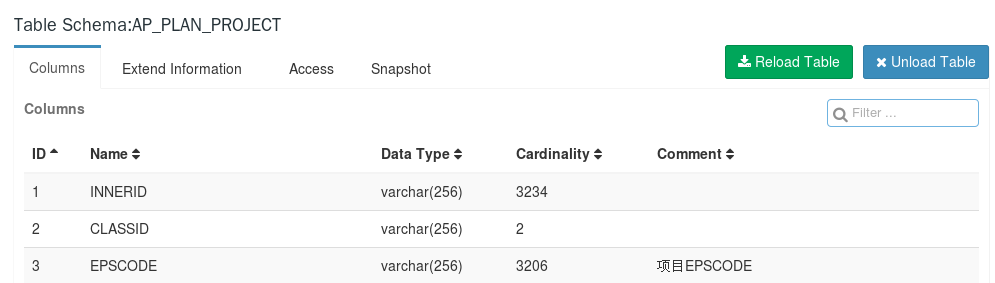
分为六个功能点:重载数据表(Reload Table)、删除数据表(Unload Table)、列信息(Columns)、元数据(Extend Information)、权限(Access)、快照(Snapshot)
参考如下:
**重载数据表** ==该功能当前阶段可以不用考虑==
根据目前测试,当我更改表结构后,使用功能后,展现的依然是以前的表结构,此处可能是个bug.
**删除数据表**
从加载的数据表中删除某个加载的表。
**列信息**
列信息包括:编号id、列名(Name)、数据类型(Data Type)、基数(Cardinality)、注释(Comment)

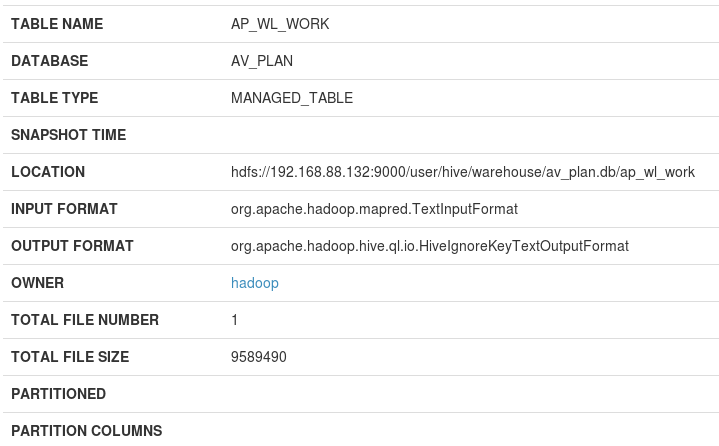
**元数据**
元数据信息主要包括:表名(TABLE NAME)、数据库(DATABASE)、表类型(TABLE TYPE)、快照时间(SNAPSHOT TIME)、文件地址(LOCATION)、输入格式(INPUT FORMAT)、输出格式(OUTPUT FORMAT)、所属用户(OWNER)、表文件总数(TOTAL FILE NUMBER)、总文件大小(TOTAL FILE SIZE)、分区(PARTITIONED)、分区列(PARTITION COLUMNS)
**快照** ==该功能当前阶段可以不用考虑==
Snapshot,使用当前表数据的cuboid,在cube计算前是空,只有cube计算完后才会有这个信息展示。

**Access** ==该功能当前阶段可以不用考虑==
列出当前可操作此表的用户或角色