基本实现原理
## Docker基本实现原理
通过三个方向实现容器化技术前置:
1) 操作系统的NameSpace 隔离系统资源技术,通过隔离网络、PID进程、系统信号量、文件系统挂载、主机名与域名,来实现在同一宿主机系统中,运行不同的容器,而每个容器之间相互隔离,运行互不干扰。
2) 使用系统的Cgroups系统资源配额功能,限制资源包括CPU、Memory、Blkio(块设备)、Network 。
3) 通过OverlayFS数据存储技术,实现容器镜像的物理存储与新建容器存储。
对于进程来说,它的静态表现就是程序,平常都安安静静地待在磁盘上;而一旦运行起来,它就变成了计算机里的数据和状态的总和,这就是它的动态表现。而容器技术的核心功能,就是通过约束和修改进程的动态表现,从而为其创造出一个“边界”。对于 Docker 等大多数 Linux 容器来说,Cgroups 技术是用来制造约束的主要手段,而 Namespace 技术则是用来修改进程视图的主要方法。你可能会觉得 Cgroups 和 Namespace 这两个概念很抽象,别担心,接下来我们一起动手实践一下,你就很容易理解这两项技术了。
接下来,让我们首先创建一个容器来试试。
```
$ docker run -it busybox /bin/sh
/ #
```
-it 参数告诉了 Docker 项目在启动容器后,需要给我们分配一个文本输入 / 输出环境,也就是 TTY,跟容器的标准输入相关联,这样我们就可以和这个 Docker 容器进行交互了。而 /bin/sh 就是我们要在 Docker 容器里运行的程序。所以,上面这条指令翻译成人类的语言就是:请帮我启动一个容器,在容器里执行 /bin/sh,并且给我分配一个命令行终端跟这个容器交互。
```
/ # ps
PID USER TIME COMMAND
1 root 0:00 /bin/sh
10 root 0:00 ps
```
可以看到,我们在 Docker 里最开始执行的 /bin/sh,就是这个容器内部的第 1 号进程(PID=1),而这个容器里一共只有两个进程在运行。这就意味着,前面执行的 /bin/sh,以及我们刚刚执行的 ps,已经被 Docker 隔离在了一个跟宿主机完全不同的世界当中。
本来,每当我们在宿主机上运行了一个 /bin/sh 程序,操作系统都会给它分配一个进程编号,比如 PID=100。这个编号是进程的唯一标识,就像员工的工牌一样。而现在,我们要通过 Docker 把这个 /bin/sh 程序运行在一个容器当中。这种机制,其实就是对被隔离应用的进程空间做了手脚,使得这些进程只能看到重新计算过的进程编号,比如 PID=1。可实际上,他们在宿主机的操作系统里,还是原来的第 100 号进程。这种技术,就是 Linux 里面的 Namespace 机制。而 Namespace 的使用方式也非常有意思:它其实只是 Linux 创建新进程的一个可选参数。我们知道,在 Linux 系统中创建进程的系统调用是 clone(),比如:
```
int pid = clone(main_function, stack_size, SIGCHLD, NULL);
```
这个系统调用就会为我们创建一个新的进程,并且返回它的进程号 pid。而当我们用 clone() 系统调用创建一个新进程时,就可以在参数中指定 CLONE_NEWPID 参数,比如:
```
int pid = clone(main_function, stack_size, CLONE_NEWPID | SIGCHLD, NULL);
```
这时,新创建的这个进程将会“看到”一个全新的进程空间,在这个进程空间里,它的 PID 是 1。之所以说“看到”,是因为这只是一个“障眼法”,在宿主机真实的进程空间里,这个进程的 PID 还是真实的数值,比如 100。当然,我们还可以多次执行上面的 clone() 调用,这样就会创建多个 PID Namespace,而每个 Namespace 里的应用进程,都会认为自己是当前容器里的第 1 号进程,它们既看不到宿主机里真正的进程空间,也看不到其他 PID Namespace 里的具体情况。而除了我们刚刚用到的 PID Namespace,Linux 操作系统还提供了 Mount、UTS、IPC、Network 和 User 这些 Namespace,用来对各种不同的进程上下文进行“障眼法”操作。比如,Mount Namespace,用于让被隔离进程只看到当前 Namespace 里的挂载点信息;Network Namespace,用于让被隔离进程看到当前 Namespace 里的网络设备和配置。这,就是 Linux 容器最基本的实现原理了。
**所以说,容器,其实是一种特殊的进程而已。**
OverlayFS是一种堆叠文件系统,它依赖并建立在其它的文件系统之上(例如ext4fs和xfs等),并不直接参与磁盘空间结构的划分,仅仅将原来系统文件中的文件或者目录进行“合并一起”,最后向用户展示"合并"的文件是在同一级的目录,这就是联合挂载技术,相对于AUFS(<1.12早期使用的存储技术) , OverlayFS速度更快,实现更简单。
Linux内核为Docker提供的OverlayFS驱动有两种: Overlay 和Overlay2。而Overlay2是相对于Overlay的一种改进在lnode利用率方面比Overlay更有效。但是Overlay有环境需求: Docker 版本17.06.02+,宿主机文件系统需要是EXT4或XFS格式。
OverlayFS通过三个目录: lower 目录、upper 目录、以及work目录实现,其中lower目录可以是多个, upper目录为可以进行读写操作的目录, work目录为工作基础目录,挂载后内容会被清空,且在使用过程中其内容用户不可见,最后联合挂载完成给用户呈现的统一视图称为merged目录。
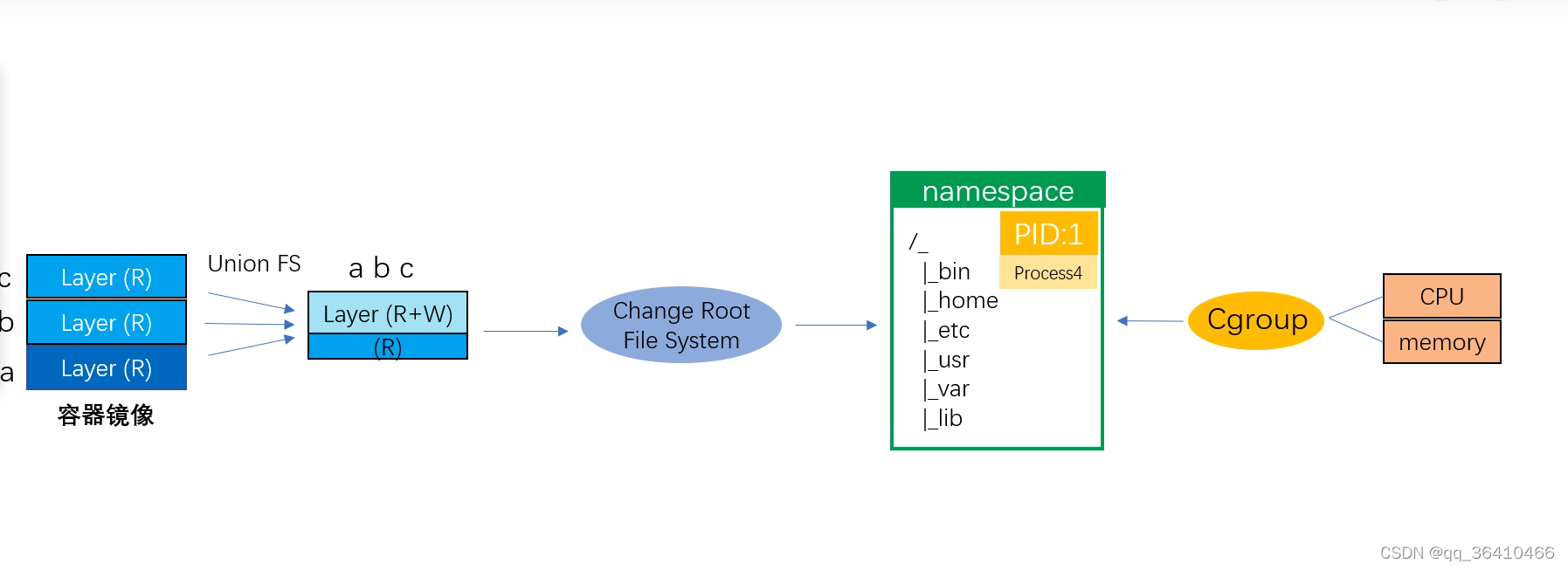
容器镜像通过联合文件系统将不同的目录挂载到同一个虚拟文件系统下,镜像由多隔层组成,在启动容器时创建一个新的层叠加上去作为一个可读可写层,然后通过change root(chroot dir/)对根目录进行一个限制,在通过namespace命名空间对内核全局资源进行封装,达到资源隔离的目的。Cgroup技术对一组进程的cpu,内存,磁盘io,网络带宽等资源进行限制。
### OverlayFS
`https://github.com/cncamp/101/tree/master/module3`
```
$ mkdir upper lower merged work
$ echo "from lower" > lower/in_lower.txt
$ echo "from upper" > upper/in_upper.txt
$ echo "from lower" > lower/in_both.txt
$ echo "from upper" > upper/in_both.txt
$ sudo mount -t overlay overlay -o lowerdir=`pwd`/lower,upperdir=`pwd`/upper,workdir=`pwd`/work `pwd`/merged
$ cat merged/in_both.txt
```
```
$ echo 'new file' > merged/new_file
$ ls -l */new_file
```
```
$ rm merged/in_both.txt
$ ls -l upper/in_both.txt lower/in_both.txt merged/in_both.txt
```
```
$ mount -t overlay overlay -o lowerdir:/dir1:/dir2:/dir3:...:/dir25,upperdir=...
```
### Namespace
```
$ lsns -t net
$ cd /proc/25452/ns/
$ nsenter -t <pid> -n ip addr
```
### cgroups
```
$ cat /proc/25452/cgroup
11:pids:/kubepods/besteffort/pod8d80a5f8-cb1e-4b28-ba54-393e6b363e20/a99d384f32fc7aeb8a06934e387ed9ea30992676257a61af37d705805f1dffb7
10:freezer:/kubepods/besteffort/pod8d80a5f8-cb1e-4b28-ba54-393e6b363e20/a99d384f32fc7aeb8a06934e387ed9ea30992676257a61af37d705805f1dffb7
9:hugetlb:/kubepods/besteffort/pod8d80a5f8-cb1e-4b28-ba54-393e6b363e20/a99d384f32fc7aeb8a06934e387ed9ea30992676257a61af37d705805f1dffb7
8:perf_event:/kubepods/besteffort/pod8d80a5f8-cb1e-4b28-ba54-393e6b363e20/a99d384f32fc7aeb8a06934e387ed9ea30992676257a61af37d705805f1dffb7
7:blkio:/kubepods/besteffort/pod8d80a5f8-cb1e-4b28-ba54-393e6b363e20/a99d384f32fc7aeb8a06934e387ed9ea30992676257a61af37d705805f1dffb7
6:cpuset:/kubepods/besteffort/pod8d80a5f8-cb1e-4b28-ba54-393e6b363e20/a99d384f32fc7aeb8a06934e387ed9ea30992676257a61af37d705805f1dffb7
5:memory:/kubepods/besteffort/pod8d80a5f8-cb1e-4b28-ba54-393e6b363e20/a99d384f32fc7aeb8a06934e387ed9ea30992676257a61af37d705805f1dffb7
4:devices:/kubepods/besteffort/pod8d80a5f8-cb1e-4b28-ba54-393e6b363e20/a99d384f32fc7aeb8a06934e387ed9ea30992676257a61af37d705805f1dffb7
3:cpu,cpuacct:/kubepods/besteffort/pod8d80a5f8-cb1e-4b28-ba54-393e6b363e20/a99d384f32fc7aeb8a06934e387ed9ea30992676257a61af37d705805f1dffb7
2:net_cls,net_prio:/kubepods/besteffort/pod8d80a5f8-cb1e-4b28-ba54-393e6b363e20/a99d384f32fc7aeb8a06934e387ed9ea30992676257a61af37d705805f1dffb7
1:name=systemd:/kubepods/besteffort/pod8d80a5f8-cb1e-4b28-ba54-393e6b363e20/a99d384f32fc7aeb8a06934e387ed9ea30992676257a61af37d705805f1dffb7
```
```
$ docker inspect <containerid>| grep -i cgroup
"CgroupParent": "kubepods-burstable-podfc9d9da9_7d7a_4970_b306_8ee27f121de1.slice",
$ cd /sys/fs/cgroup/memory/kubepods.slice/kubepods-burstable.slice
$ cd kubepods-burstable-podfc9d9da9_7d7a_4970_b306_8ee27f121de1.slice
$ ls
$ cat memory.limit_in_bytes
1073741824
```
## Docker 优势与局限性
**优势**
1) Docker 让软件开发者与维护人员可以非常方便的启动应用程序以及将程序的依赖,包到一个容器中,然后启动Docker应用到支持Docker的系统平台中,就可以实现应用虚拟化。
2) Docker 镜像中包含了应用运行环境和配置文件,所以Docker可以简化部署多种应用的工作。比如说Web应用、后台应用(Java/C++). 数据库应用、Hadoop集群、消息队列等等都可以打包成一-个个独立的Docker应用镜像来部署。
3) 提升宿主机(物理服务器/云虚拟机),系统资源的利用率。
**局限性**
1) 基本的Docker网络管理模式比较简单,主要是基于系统使用Namespace隔离。
2) 与其他系统的网络连通性,使用自定义的地址网段,需要借助其他插件实现与其他网段的互通,提高了网络的整体复杂度。
3) 容器中应用程序日志不方便查看与收集。
4) 容器中无法运行Windows。
### Dokcer 架构与术语
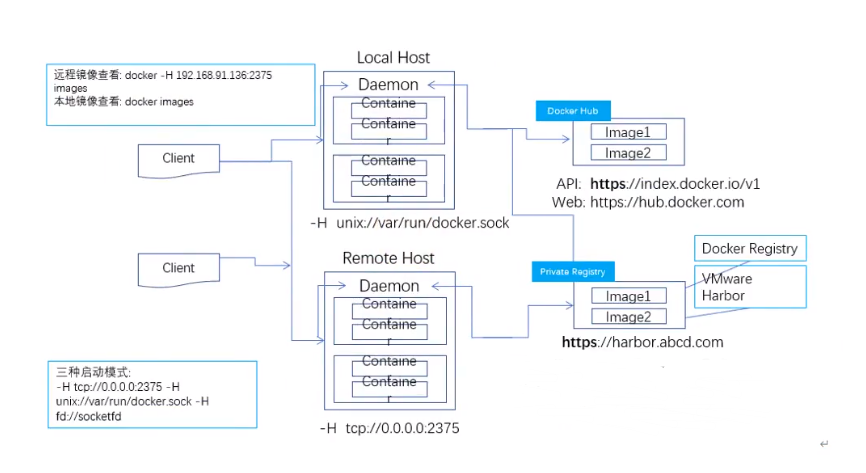
Docker使用客户端-服务器(C/S) 架构模式,即可使用远程API来管理服务端和创建容器。
Docker容器需要通过Docker镜像来创建。
#### Docker C/S架构逻辑图
1) Docker分为客户端与服务端,客户端可以管理本地的服务端(默认),也可以管理远程的服务端。
## 分析镜像存储结构
### 获取镜像存储路径
通过镜像信息获取到物理存储位置
```
# docker inspect httpgo:latest
[
{
"Id": "sha256:1f8dfa903cd11027a6378257e19dcecbfdf32066e6714b47f17e034e0aea7738",
...
...
"Data": {
"LowerDir": "/var/lib/docker/overlay2/cec8127bb4a73ab4d31cb00adf523d753459cee7860ab0917bd4e45acf9aefa8/diff",
"MergedDir": "/var/lib/docker/overlay2/fd71e587195a9538ea0ce66bd10ec6cdfc6fc07cb97277117b50498b4850555d/merged",
"UpperDir": "/var/lib/docker/overlay2/fd71e587195a9538ea0ce66bd10ec6cdfc6fc07cb97277117b50498b4850555d/diff",
#自动生成 默认空 挂载时候用
"WorkDir": "/var/lib/docker/overlay2/fd71e587195a9538ea0ce66bd10ec6cdfc6fc07cb97277117b50498b4850555d/work"
},
"Name": "overlay2"
},
"RootFS": {
"Type": "layers",
"Layers": [
"sha256:74ddd0ec08fa43d09f32636ba91a0a3053b02cb4627c35051aff89f853606b59",
"sha256:095ab4e64312ca2d9b14d0dbb2d7813c9720c11a5c88d33650ccd36d90800892"
]
},
"Metadata": {
"LastTagTime": "2022-02-21T14:32:56.860059217+08:00"
}
}
]
```
### 分析Lower层
LowerDir层的存储是不允许创建文件,此时的LowerDir实际 上是其他的镜像的UpperDir层,也就是说在构建镜像的时候,如果发现构建的内容相同,那么不会重复的构建目录,而是使用其他镜像的Upper层来作为本镜像的Lower
### 分析Upper层
在Upper层创建文件