CSI
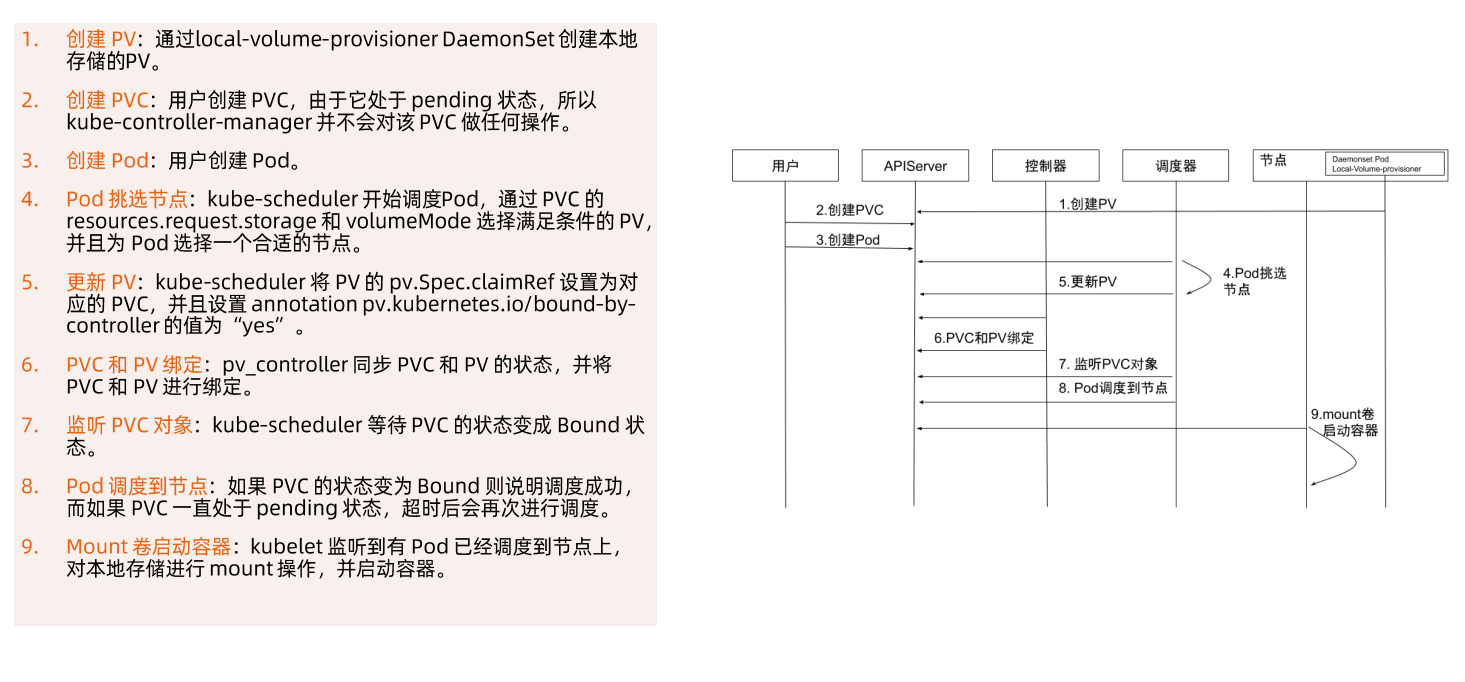
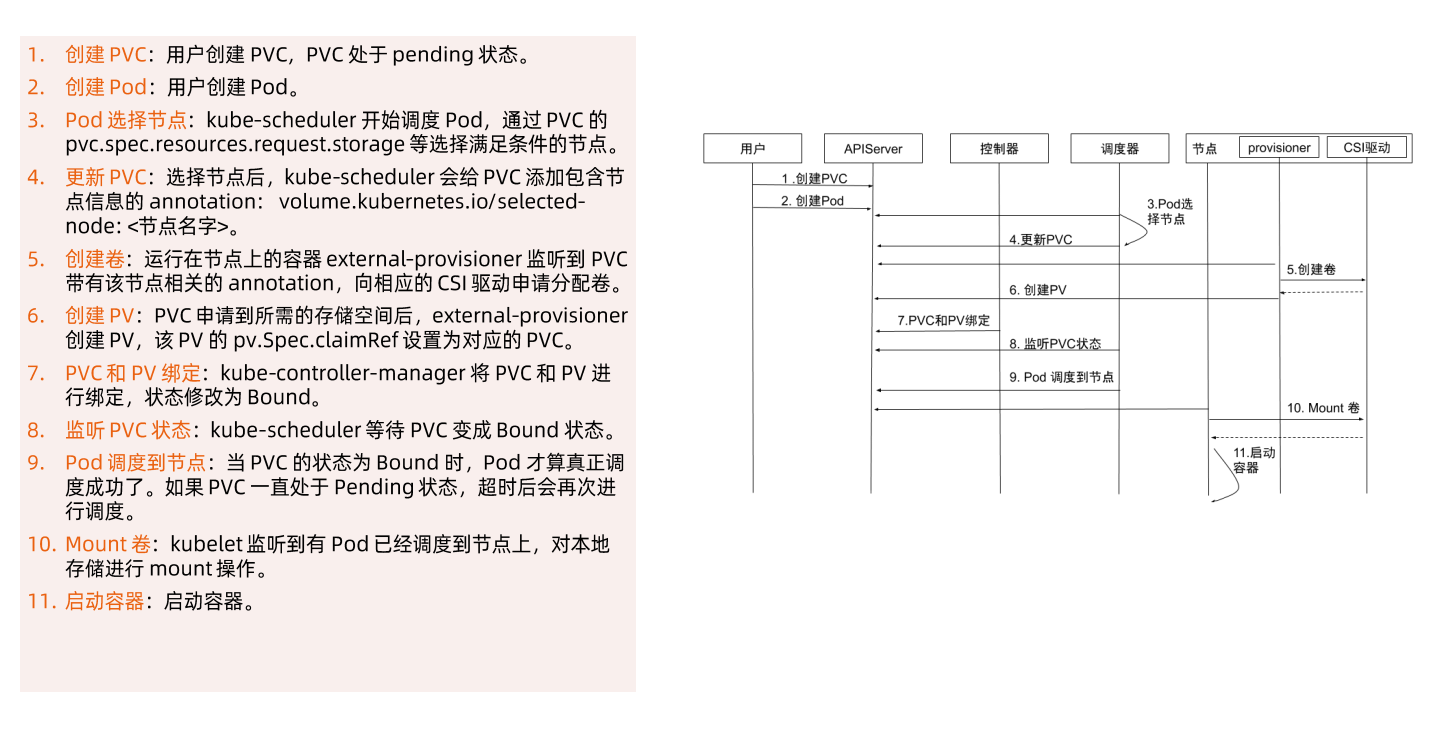
# CSI
## 容器运行时存储
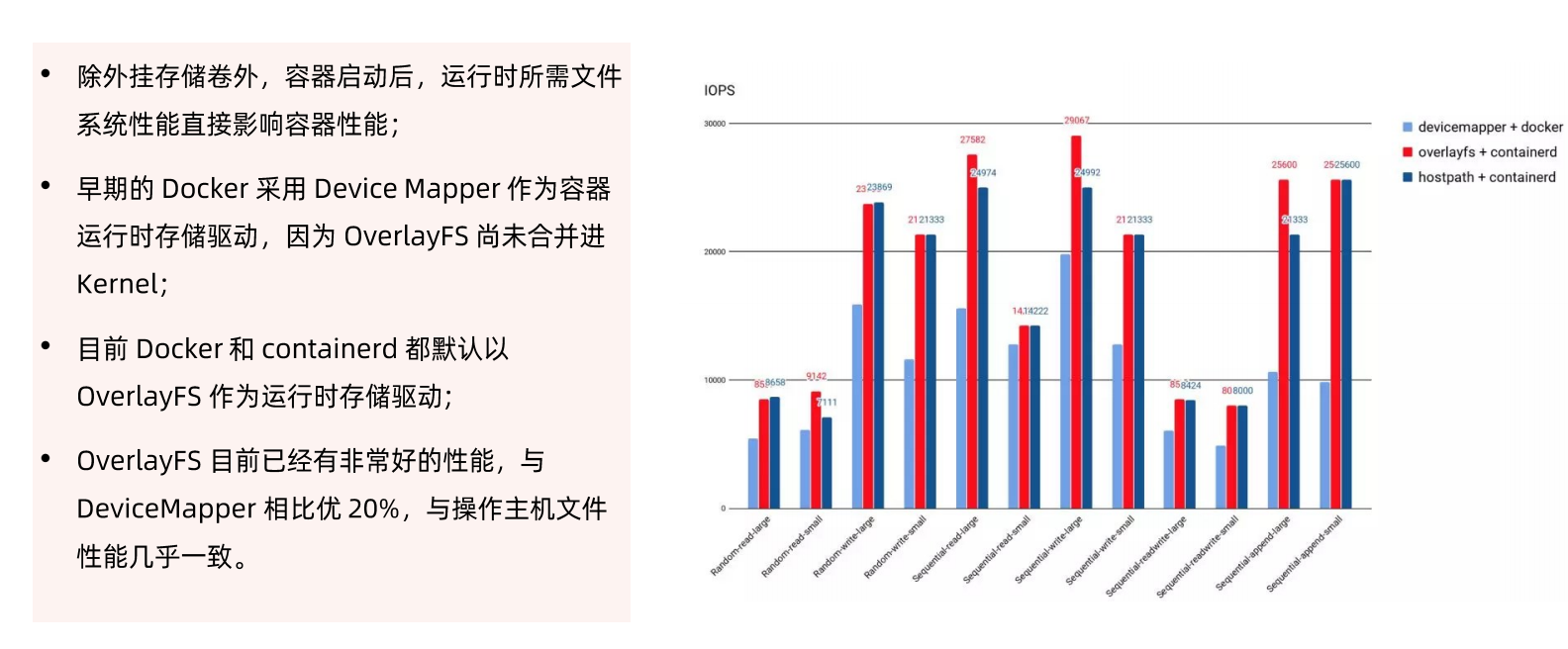
### 存储插件管理

#### out-of-tree CSI插件

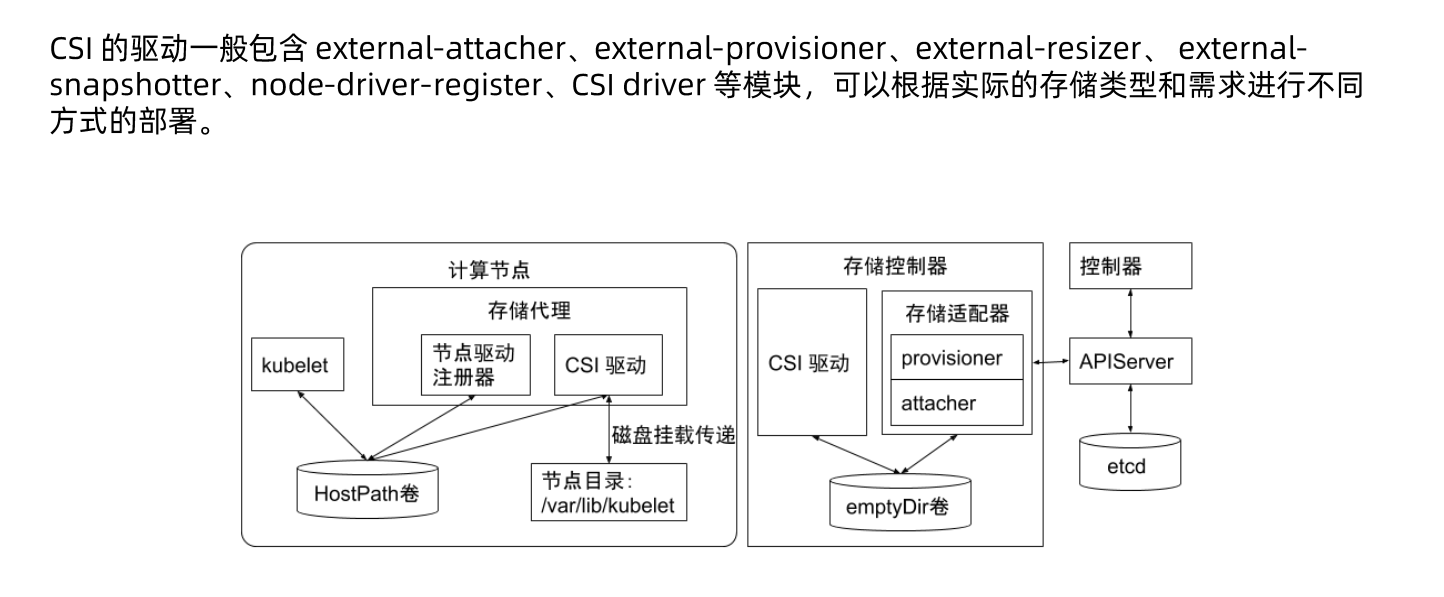
### CSI 驱动
## 临时存储
常见的临时存储主要就是emptyDir卷。
emptyDir是-种经常被用户使用的卷类型,顾名思义,“卷” 最初是空的。当Pod从节点上删除时,emptyDir卷中的数据也会被永久删除。但当Pod的容器因为某些原因退出再重启时,emptyDir 卷内的数据并不会丢失。
默认情况下,emptyDir 卷存储在支持该节点所使用的存储介质上,可以是本地磁盘或网络存储。
emptyDir也可以通过将emptyDir.medium字段设置为"Memory" 来通知Kubernetes为容器安装tmpfs,此时数据被存储在内存中,速度相对于本地存储和网络存储快很多。但是在节点重启的时候,内存数据会被清除;而如果存在磁盘上,则重启后数据依然存在。另外,使用tmpfs的内存也会计入容器的使用内存总量中,受系统的Cgroup限制。
emptyDir设计的初衷主要是给应用充当缓存空间,或者存储中间数据,用于快速恢复。然而,这并不是说满足以上需求的用户都被推荐使用emptyDir,我们要根据用户业务的实际特点来判断是否使用emptyDir。因为emptyDir的空间位于系统根盘,被所有容器共享,所以在磁盘的使用率较高时会触发Pod的eviction操作,从而影响业务的稳定。
## 半持久化存储
常见的半持久化存储主要是hostPath卷。hostPath 卷能将主机节点文件系统上的文件或目录挂载到指定Pod中。对普通用户而言一般不需要这样的卷,但是对很多需要获取节点系统信息的Pod而言,却是非常必要的。
例如,hostPath的用法举例如下:
●某个Pod需要获取节点上所有Pod的log,可以通过hostPath访问所有Pod的stdout输出存储目录,例如/var/log/pods路径。
●某个Pod需要统计系统相关的信息,可以通过hostPath访问系统的/proc目录。
使用hostPath的时候,除设置必需的path属性外,用户还可以有选择性地为hostPath卷指定类型,支持类型包含目录、字符设备、块设备等。
使用同一个目录的Pod可能会由于调度到不同的节点,导致目录中的内容有所不同。Kubernetes在调度时无法顾及由hostPath使用的资源。Pod被删除后,如果没有特别处理,那么hostPath上写的数据会遗留到节点上,占用磁盘空间。
## 持久化存储
支持持久化的存储是所有分布式系统所必备的特性。针对持久化存储,Kubernetes 引入了StorageClass、Volume、 PVC ( Persistent Volume Claim)、PV (Persitent Volume)的概念,将存储独立于Pod的生命周期来进行管理。
Kuberntes目前支持的持久化存储包含各种主流的块存储和文件存储,譬如awsElasticBlockStore、azureDisk、cinder、 NFS、 cephfs、 iscsi 等,在大类上可以将其分为网络存储和本地存储两种类型。

### PVC
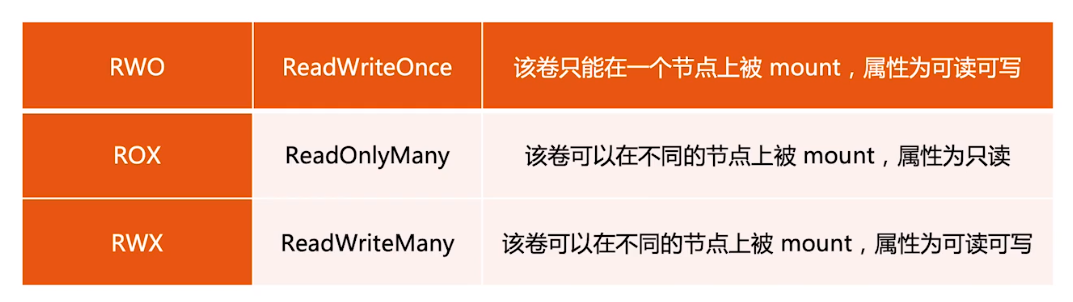
由用户创建,代表用户对存储需求的声明,主要包含需要的存储大小、存储卷的访问模式、StroageClass等类型,其中存储卷的访问模式必须与存储的类型一致。
### PV
由集群管理员提前创建,或者根据PVC的申请需求动态地创建,它代表系统后端的真实的存储空间,可以称之为卷空间。
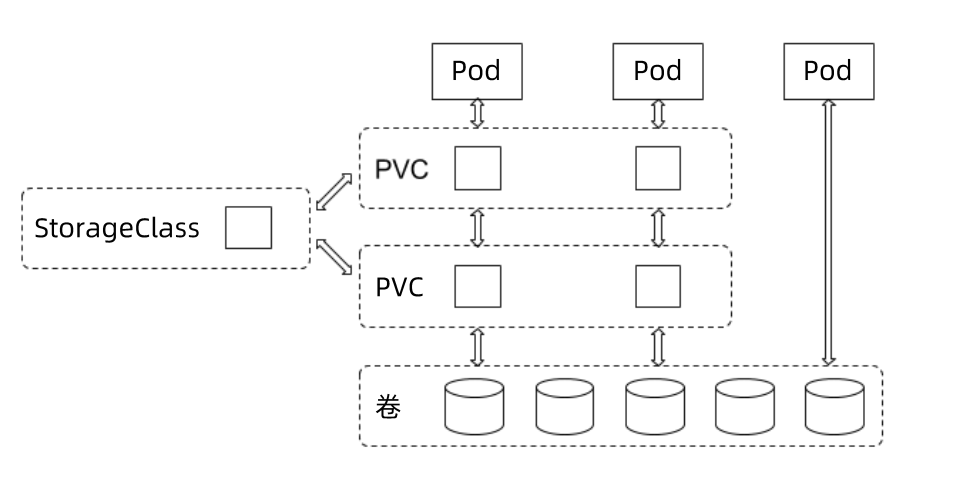
### 存储对象关系
用户通过创建PVC来申请存储。控制器通过PVC的StorageClass和请求的大小声明来存储后端创建卷,进而创建PV, Pod通过指定PVC来引用存储。
```
PVC是持久化存储的接口,提供了对存储的具体描述,但不提供具体实现;而PV就是用来具体实现存储的。
然后当我们创建大量的 PVC 的时候,就需要运维提前准备好大量的 PV 。而这一切全
部靠运维手动来创建是不可能的。那么我们就需要一个自动化创建PV的机制:
Dynamic Provisioning,而这个机制的具体实现就是 StorageClass。
StorageClass其实就是为PV创建模版,具体会定义以下2个部分:
PV的属性。比如:存储类型,Volume的大小等。
PV需要用到的存储插件类型:比如Ceph,腾讯云的CBS等。
```
不同介质类型的磁盘,需要设置不同的StorageClass,以便让用户做区分。StorageClass需要设置磁盘介质的类型,以便用户了解该类存储的属性。
在本地存储的PV静态部署模式下,每个物理磁盘都尽量只创建一个PV,而不是划分为多个分区来提供多个本地存储PV,避免在使用时分区之间的I/0干扰。
本地存储需要配合磁盘检测来使用。当集群部署规模化后,每个集群的本地存储PV可能会超过几万个,如磁盘损坏将是频发事件。此时,需要在检测到磁盘损坏、丢盘等问题后,对节点的磁盘和相应的本地存储PV进行特定的处理,例如触发告警、自动cordon节点、自动通知用户等。
对于提供本地存储节点的磁盘管理,需要做到灵活管理和自动化。节点磁盘的信息可以归一、集中化管理。在local-volume-provisioner中增加部署逻辑,当容器运行起来时,拉取该节点需要提供本地存储的磁盘信息,例如磁盘的设备路径,以Filesystem或Block的模式提供本地存储,或者是否需要加入某个LVM的虚拟组(VG)等。
local-volume-provisioner根据获取的磁盘信息对磁盘进行格式化,或者加入到某个VG,从而形成对本地存储支持的自动化闭环。
### 独占的Local Volume
### Dynamic Local Volume
CSI驱动需要汇报节点_上相关存储的资源信息,以便用于调度。
但是机器的厂家不同,汇报方式也不同。
例如,有的厂家的机器节点上具有NVMe、SSD、 HDD等多种存储介质,希望将这些存储介质分别进行汇报。
这种需求有别于其他存储类型的CSI驱动对接口的需求,因此如何汇报节点的存储信息,以及如何让节点的存储信息应用于调度,目前并没有形成统一的意见。
集群管理员可以基于节点存储的实际情况对开源CSI驱动和调度进行一些代码修改,再进行部署和使用。
如果将磁盘空间作为一个存储池(例如LVM)来动态分配,那么在分配出来的逻辑卷空间的使用上,可能会受到其他逻辑卷的I/O干扰,因为底层的物理卷可能是同一个。
如果PV后端的磁盘空间是一块独立的物理磁盘,则I/O就不会受到干扰。
# ROOK
Rook是一款云原生环境下的开源分布式存储编排系统,提供平台、框架和对各种存储解决方案的支持,以和云原生环境进行本地集成。目前支持Ceph、NFS、EdgeFS、Cassandra、CockroachDB 等存储系统。
它实现了一个自动管理的、自动扩容的、自动修复的分布式存储服务。Rook支持自动部署、启动、配置、分配、扩容/缩容、升级、迁移、灾难恢复、监控以及资源管理。
rook安装:
`https://github.com/cncamp/101/blob/master/module7/csi/rook/rook.md`
## ROOK架构
## Rook Operator
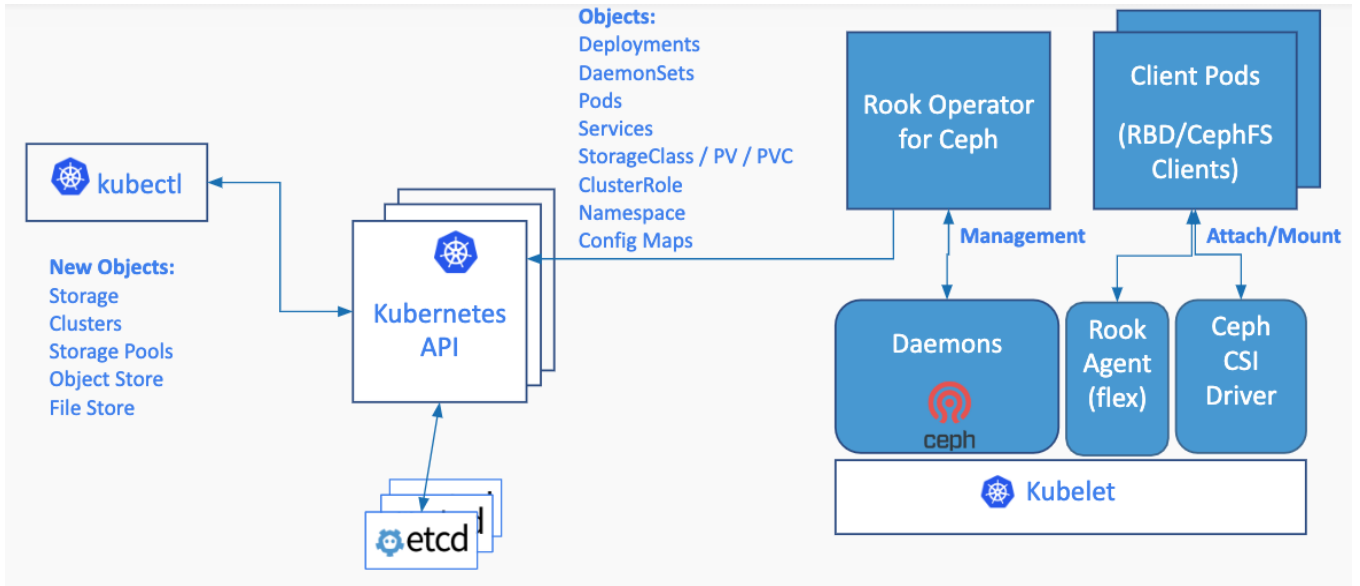
Rook Operater是Rook的大脑,以deployment形式存在。
其利用Kubernetes的controller-runtime框架实现了CRD,并进而接受ubernetes创建资源的请求并创建相关资源( 集群,pool,块存储服务,文件存储服务等)。
Rook Operater监控存储守护进程,来确保存储集群的健康。
监听RookDiscovers收集到的存储磁盘设备,并创建相应服务(Ceph的话就是OSD了)。
## Rook Discover
Rook Discover是以DaemonSet形式部署在所有的存储机上的,其检测挂接到存储节点上的存储设备。把符合要求的存储设备记录下来,这样Rook Operater感知到以后就可以基于该存储设备创建相应服务了。

## CSIDriver 发现
CSI驱动发现:
如果一个CSI驱动创建CSIDriver对象,Kubernetes 用户可以通过getCSIDriver命令发现它们;
CSI对象有如下特点:
●自定义的Kubernetes逻辑;
●Kubernetes 对存储卷有一些列操作, 这些CSIDriver可以自定义支持哪些操作?
## Provisioner
CSI external-provisioner是一个监控Kubernetes PVC对象的Sidecar容器。
当用户创建PVC后,Kubernetes 会监测PVC对应的StorageClass,如果StorageClass中的provisioner与某插件匹配,该容器通过CSI Endpoint ( 通常是unix socket)调用CreateVolume方法。
如果CreateVolume方法调用成功,则Provisioner sidecar创建Kubernetes PV对象。

Rook Agent是以DaemonSet形式部署在所有的存储机上的,其处理所有的存储操作,例如挂卸载存储卷以及格式化文件系统等。
### Storage Class

参考链接:
`https://dramasamy.medium.com/life-of-a-packet-in-kubernetes-part-2-a07f5bf0ff14`
# kubernetes 存储
kubernetes 可以存数据方式有很多,大致有两种,持久化存储与非持久化存储
- 非持久化存储主要是 `emptydir`
- 非 `emptydir` 的基本都是持久存储
Kubernetes 默认支持很多种存储,有些是内部原生支持,nfs 是内部原生支持;有些是通过接口支持,通过接口支持的好处是可以对接各家的云。
- block
- ebs
- container storage
- oss 对象存储
## PV 和 PVC
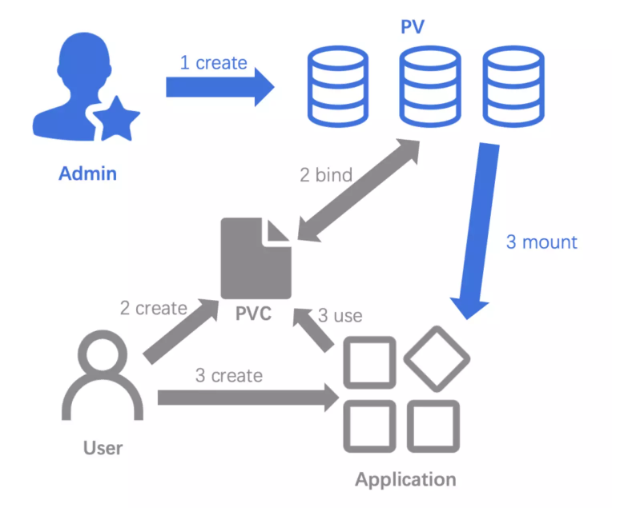
PV:PV 描述的是持久化存储卷,主要定义的是一个持久化存储在宿主机上的目录,比如一个 NFS 的挂载目录。
PVC:PVC 描述的是 Pod 所希望使用的持久化存储的属性,比如,Volume 存储的大小、可读写权限等等。
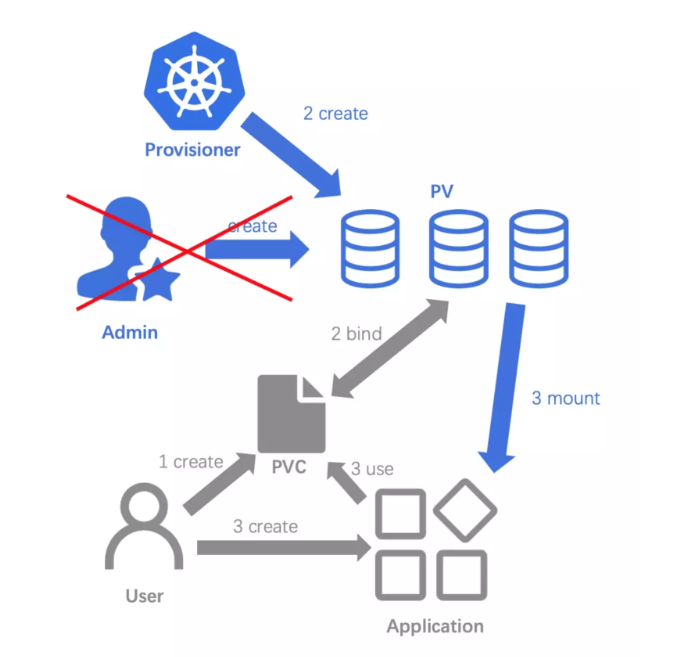
通常情况下,PV 对象是由运维人员事先创建在 Kubernetes 集群里待用的。比如,运维人员可以定义这样一个 NFS 类型的 PV,如下所示:
```
apiVersion: v1
kind: PersistentVolume
metadata:
name: nfs
spec:
storageClassName: manual
capacity:
storage: 1Gi
accessModes:
- ReadWriteMany
nfs:
server: 10.244.1.4
path: "/"
```
而 PVC 描述的,则是 Pod 所希望使用的持久化存储的属性。比如,Volume 存储的大小、可读写权限等等。
PVC 对象通常由开发人员创建;或者以 PVC 模板的方式成为 StatefulSet 的一部分,然后由 StatefulSet 控制器负责创建带编号的 PVC。比如,开发人员可以声明一个 1 GiB 大小的 PVC,如下所示:
```
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: nfs
spec:
accessModes:
- ReadWriteMany
storageClassName: manual
resources:
requests:
storage: 1Gi
```
而用户创建的 PVC 要真正被容器使用起来,就必须先和某个符合条件的 PV 进行绑定。这里要检查的条件,包括两部分:
- 第一个条件,当然是 PV 和 PVC 的 spec 字段。比如,PV 的存储(storage)大小,就必须满足 PVC 的要求。
- 而第二个条件,则是 PV 和 PVC 的 storageClassName 字段必须一样。
在成功地将 PVC 和 PV 进行绑定之后,Pod 就能够像使用 hostPath 等常规类型的 Volume 一样,在自己的 YAML 文件里声明使用这个 PVC 了,如下所示:
```
apiVersion: v1
kind: Pod
metadata:
labels:
role: web-frontend
spec:
containers:
- name: web
image: nginx
ports:
- name: web
containerPort: 80
volumeMounts:
- name: nfs
mountPath: "/usr/share/nginx/html"
volumes:
- name: nfs
persistentVolumeClaim:
claimName: nfs
```
## StorageClass
PV 和 PVC 方法虽然能实现屏蔽底层存储,但是 PV 创建比较复杂,通常都是由集群管理员管理,这非常不方便。
Kubernetes 解决这个问题的方法是提供动态配置 PV 的方法,可以自动创 PV。
- 管理员可以部署 PV 配置器(provisioner),然后定义对应的 StorageClass,
- 这样开发者在创建 PVC 的时候就可以选择需要创建存储的类型,
- PVC 会把 StorageClass 传递给 PV provisioner,由 provisioner 自动创建 PV。
- 在声明 PVC 时加上 StorageClassName,就可以自动创建 PV,并自动创建底层的存储资源。
具体地说,StorageClass 对象会定义如下两个部分内容:
- 第一,PV 的属性。比如,存储类型、Volume 的大小等等。
- 第二,创建这种 PV 需要用到的存储插件。比如,Ceph 等等。
有了这样两个信息之后,Kubernetes 就能够根据用户提交的 PVC,找到一个对应的 StorageClass 了。然后,Kubernetes 就会调用该 StorageClass 声明的存储插件,创建出需要的 PV。
举个例子,假如我们的 Volume 的类型是 GCE 的 Persistent Disk 的话,运维人员就需要定义一个如下所示的 StorageClass:
```
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: block-service
provisioner: kubernetes.io/gce-pd
parameters:
type: pd-ssd
```
在这个 YAML 文件里,我们定义了一个名叫 block-service 的 StorageClass。
这个 StorageClass 的 provisioner 字段的值是:kubernetes.io/gce-pd,这正是 Kubernetes 内置的 GCE PD 存储插件的名字。
而这个 StorageClass 的 parameters 字段,就是 PV 的参数。比如:上面例子里的 type=pd-ssd,指的是这个 PV 的类型是“SSD 格式的 GCE 远程磁盘”。
需要注意的是,由于需要使用 GCE Persistent Disk,上面这个例子只有在 GCE 提供的 Kubernetes 服务里才能实践。如果你想使用我们之前部署在本地的 Kubernetes 集群以及 Rook 存储服务的话,你的 StorageClass 需要使用如下所示的 YAML 文件来定义:
```
apiVersion: ceph.rook.io/v1beta1
kind: Pool
metadata:
name: replicapool
namespace: rook-ceph
spec:
replicated:
size: 3
---
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: block-service
provisioner: ceph.rook.io/block
parameters:
pool: replicapool
#The value of "clusterNamespace" MUST be the same as the one in which your rook cluster exist
clusterNamespace: rook-ceph
```
在这个 YAML 文件中,我们定义的还是一个名叫 block-service 的 StorageClass,只不过它声明使的存储插件是由 Rook 项目。
有了 StorageClass 的 YAML 文件之后,运维人员就可以在 Kubernetes 里创建这个 StorageClass 了,作为应用开发者,只需要在 PVC 里指定要使用的 StorageClass 名字即可,如下所示:
```
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: claim1
spec:
accessModes:
- ReadWriteOnce
storageClassName: block-service
resources:
requests:
storage: 30Gi
```
可以看到,我们在这个 PVC 里添加了一个叫作 storageClassName 的字段,用于指定该 PVC 所要使用的 StorageClass 的名字是:block-service。
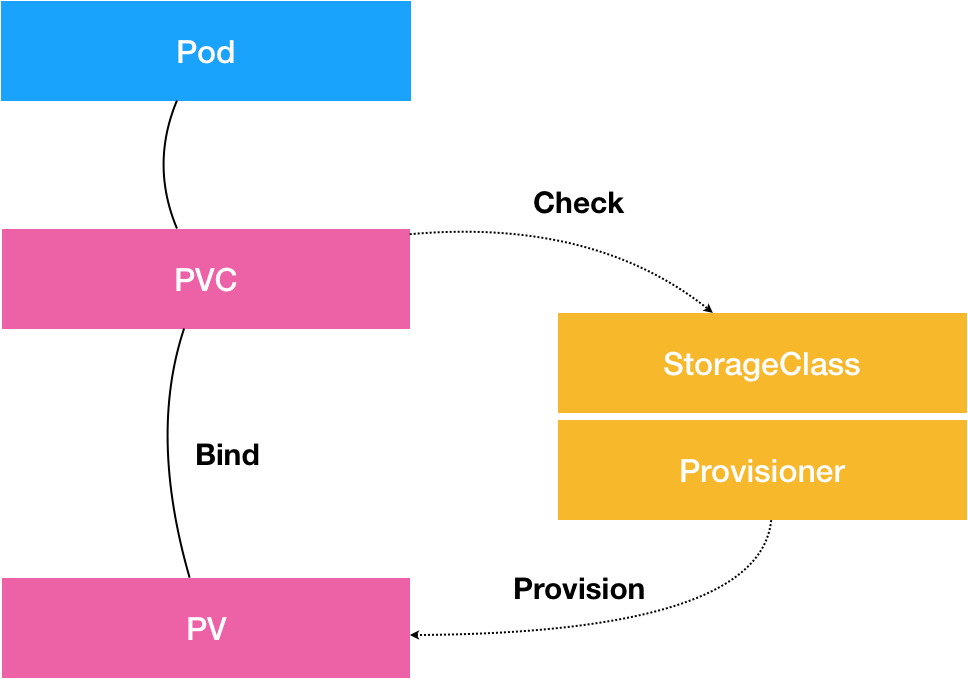
从图中我们可以看到,在这个体系中:
- PVC 描述的,是 Pod 想要使用的持久化存储的属性,比如存储的大小、读写权限等。
- PV 描述的,则是一个具体的 Volume 的属性,比如 Volume 的类型、挂载目录、远程存储服务器地址等。
- 而 StorageClass 的作用,则是充当 PV 的模板。并且,只有同属于一个 StorageClass 的 PV 和 PVC,才可以绑定在一起。
当然,StorageClass 的另一个重要作用,是指定 PV 的 Provisioner(存储插件)。这时候,如果你的存储插件支持 Dynamic Provisioning 的话,Kubernetes 就可以自动为你创建 PV 了。