控制平面组件调度器
## kube-scheduler
kube-scheduler负责分配调度Pod到集群内的节点上,它监听kube-apiserver,查询还未分配Node的Pod,然后根据调度策略为这些Pod分配节点(更新Pod的NodeName字段)
调度器需要充分考虑诸多的因素:
- 公平调度;
- 资源高效利用;
- QoS;
- affinity和anti-affinity;
- 数据本地化(data locality) ;
- 内部负载干扰(inter-workload interference) ;
- deadlines。
kube-scheduler调度分为两个阶段,predicate 和priority(预选和优选):
- predicate:过滤不符合条件的节点;
- priority:优先级排序,选择优先级最高的节点。
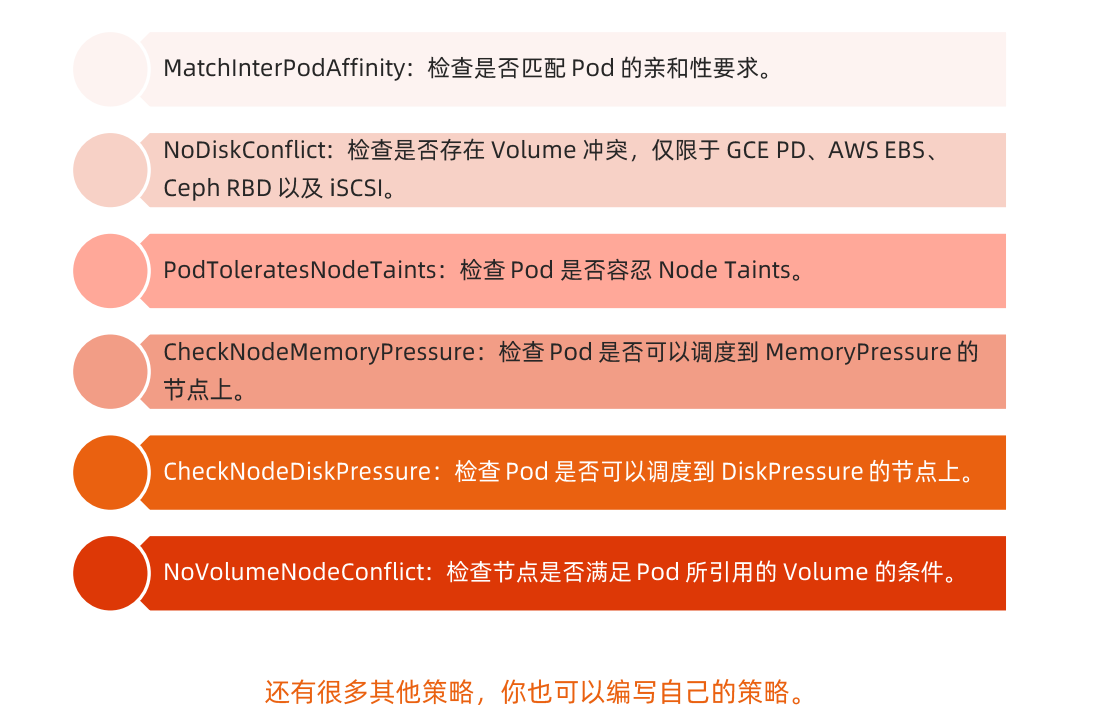
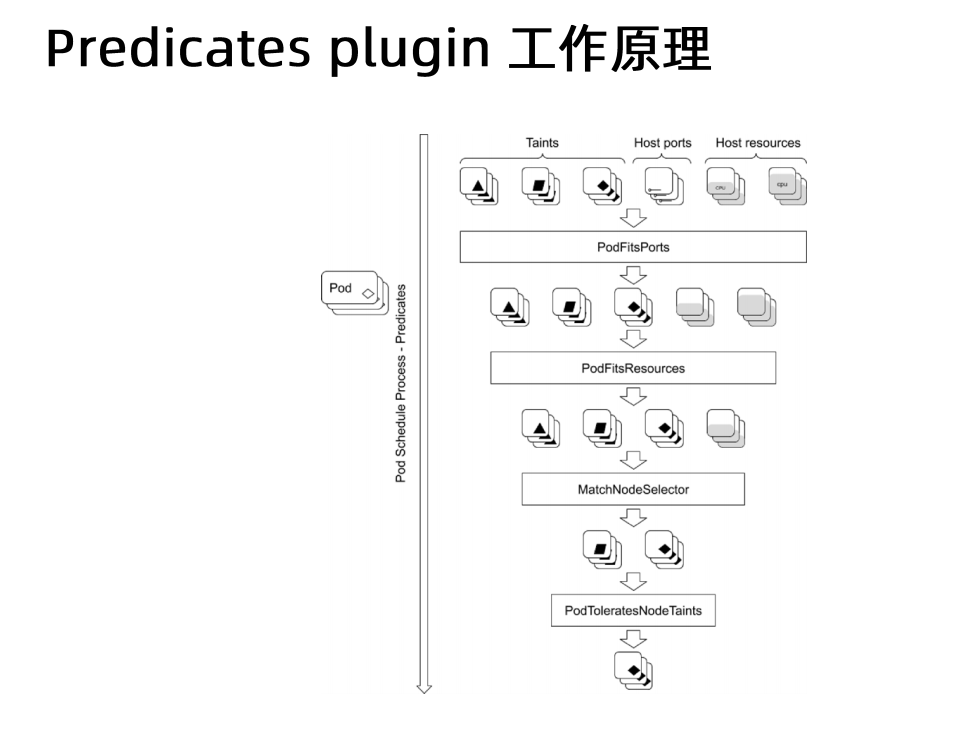
### predicate 预选

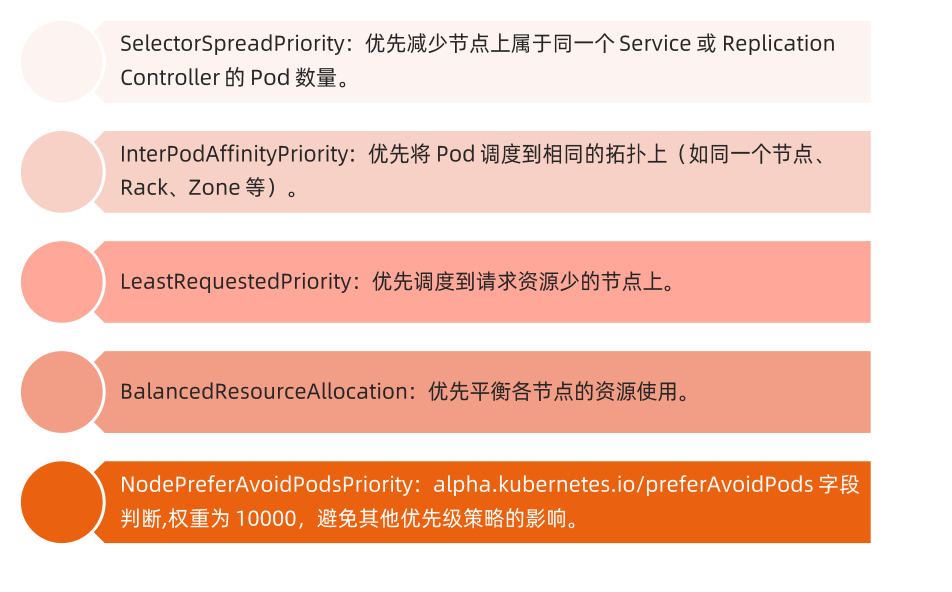
### priority 优选

## 资源需求

```yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
resources:
limits:
memory: 1Gi
cpu: 1
requests:
memory: 256Mi
cpu: 100m
```
1. requests是调度器调度的时候,会来解读pod的requests,requests的语义是说我最少需要这么多的资源,如果节点没有达到,requests需要的资源,是不能调度过去的
2. limits是这个应用最多需要的资源,由linux的cgroup技术来管控配额
### 磁盘资源需求
容器临时存储(ephemeral storage)包含日志和可写层数据,可以通过定义Pod Spec中的limits.ephemeral-storage和requests.ephemeral-storage来申请。
Pod调度完成后,计算节点对临时存储的限制不是基于cgroup的,而是由kubelet定时获取容器的日志和容器可写层的磁盘使用情况,如果超过限制,则会对Pod进行驱逐。
### Init Container的资源需求
●当kube-scheduler调度带有多个init容器的Pod时,只计算cpu.request最多的init容器,而不是计算所有的init容器总和。
●由于多个init容器按顺序执行,并且执行完成立即退出,所以申请最多的资源init容器中的所需资源,即可满足所有init容器需求。
●kube-scheduler 在计算该节点被占用的资源时,init容器的资源依然会被纳入计算。 因为init容器在特定情况下可能会被再次执行,比如由于更换镜像而引起Sandbox重建时。
```yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
initContainers:
- name: init-myservice
image: busybox:1.28
command: ['sh', '-c', 'echo The app is running! && sleep 10']
containers:
- name: nginx
image: nginx
```
有些时候,用户不想定义资源,但是我希望在这个namespace里面给他定义一个默认资源,也就是说凡是你不填资源的,那么就会用这个默认资源LimitRange,或者说限定某一个namespace他的pod所能引用的这些资源的一个范围 ,限制你能使用的资源的一个上限,这个对象就叫LimitRange。
- 当一个deployment没有写资源需求,配合LimitRange给他一个资源
```yaml
apiVersion: v1
kind: LimitRange
metadata:
name: mem-limit-range
spec:
limits:
- default:
memory: 512Mi
defaultRequest:
memory: 256Mi
type: Container
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
```
## 把pod调度到指定的node上
可以通过nodeSelector、nodeAffinity、podAffinity以及Taints和tolerations等来将Pod调度到需要的Node上。
也可以通过设置nodeName参数,将Pod调度到指定Node节点上。
比如,使用nodeSelector,首先给Node加上标签:
kubectl label nodes <your-node-name> disktype=ssd
接着,指定该Pod只想运行在带有disktype=ssd标签的Node上。
- 案例
```yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
nodeSelector:
disktype: ssd
```
### nodeAffinity
`nodeAffinity目前支持两种: requiredDuringSchedulinglgnoredDuringExecution 和preferredDuringSchedulinglgnoredDuringExecution,分别代表必须满足条件和优选条件。`
节点亲和性,比上面的`nodeSelector`更加灵活,它可以进行一些简单的逻辑组合,不只是简单的相等匹配 。分为两种,软策略和硬策略。
- preferredDuringSchedulingIgnoredDuringExecution:软策略,如果你没有满足调度要求的节点的话,Pod就会忽略这条规则,继续完成调度过程,说白了就是满足条件最好了,没有满足就忽略掉的策略。
- requiredDuringSchedulingIgnoredDuringExecution : 硬策略,如果没有满足条件的节点的话,就不断重试直到满足条件为止,简单说就是你必须满足我的要求,不然我就不会调度Pod。
比如下面的例子代表调度到包含标签Kubernetes.io/e2e-az-name并且值为e2e-az1或e2e-az2的Node上,并且优选还带有标签another-node-label-key=another-node-label-value的Node。

```yaml
#要求 Pod 不能运行在128和132两个节点上,如果有个节点满足disktype=ssd的话就优先调度到这个节点上
...
spec:
containers:
- name: demo
image: 172.21.32.6:5000/demo/myblog
ports:
- containerPort: 8002
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: NotIn
values:
- 192.168.136.128
- 192.168.136.132
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
preference:
matchExpressions:
- key: disktype
operator: In
values:
- ssd
- sas
...
```
这里的匹配逻辑是 label 的值在某个列表中,现在`Kubernetes`提供的操作符有下面的几种:
- In:label 的值在某个列表中
- NotIn:label 的值不在某个列表中
- Gt:label 的值大于某个值
- Lt:label 的值小于某个值
- Exists:某个 label 存在
- DoesNotExist:某个 label 不存在
*如果nodeSelectorTerms下面有多个选项的话,满足任何一个条件就可以了;如果matchExpressions有多个选项的话,则必须同时满足这些条件才能正常调度 Pod*
#### 案例
`hard-node-affinity.yaml`
```yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: disktype
operator: In
values:
- ssd
containers:
- name: nginx
image: nginx
```
`soft-node-affinity.yaml`
```yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
affinity:
nodeAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
preference:
matchExpressions:
- key: disktype
operator: In
values:
- ssd
containers:
- name: nginx
image: nginx
```
```sh
### 测试强亲和
kubectl apply -f hard-node-affinity.yaml
### 观察 pod
kubectl get po
kubectl describe po
### 测试弱亲和
kubectl apply -f soft-node-affinity.yaml
### 观察 pod
kubectl get po
kubectl describe po
### 为什么改成了弱亲和还 pending? 理解 apply 的可能问题
kubectl get po -oyaml
### Scheduler 扩展点
调度行为发生在一系列阶段中,这些阶段是通过以下扩展点公开的:
- QueueSort:这些插件对调度队列中的悬决的 Pod 排序。 一次只能启用一个队列排序插件。
- PreFilter:这些插件用于在过滤之前预处理或检查 Pod 或集群的信息。 它们可以将 Pod 标记为不可调度。
- Filter:这些插件相当于调度策略中的断言(Predicates),用于过滤不能运行 Pod 的节点。 过滤器的调用顺序是可配置的。 如果没有一个节点通过所有过滤器的筛选,Pod 将会被标记为不可调度。
- PreScore:这是一个信息扩展点,可用于预打分工作。
- Score:这些插件给通过筛选阶段的节点打分。调度器会选择得分最高的节点。
- Reserve:这是一个信息扩展点,当资源已经预留给 Pod 时,会通知插件。 这些插件还实现了 Unreserve 接口,在 Reserve 期间或之后出现故障时调用。
- Permit:这些插件可以阻止或延迟 Pod 绑定。
- PreBind:这些插件在 Pod 绑定节点之前执行。
- Bind:这个插件将 Pod 与节点绑定。绑定插件是按顺序调用的,只要有一个插件完成了绑定,其余插件都会跳过。绑定插件至少需要一个。
- PostBind:这是一个信息扩展点,在 Pod 绑定了节点之后调用。
```
### podAffinity
podAffinity基于Pod的标签来选择Node,仅调度到满足条件Pod所在的Node上,支持podAffinity和podAntiAffinity。这个功能比较绕,以下面的例子为例:
如果一个"Node所在Zone中包含至少一个带有security=S1标签且运行中的Pod",那么可以调度到该Node,不调度到“包含至少一个带有security=S2标签且运行中Pod”的Node上。

```yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-anti
spec:
replicas: 2
selector:
matchLabels:
app: anti-nginx
template:
metadata:
labels:
app: anti-nginx
spec:
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: a
operator: In
values:
- b
topologyKey: kubernetes.io/hostname
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- anti-nginx
topologyKey: kubernetes.io/hostname
containers:
- name: with-pod-affinity
image: nginx
```
## 污点(Taints)与容忍(tolerations)
对于`nodeAffinity`无论是硬策略还是软策略方式,都是调度 Pod 到预期节点上,而`Taints`恰好与之相反,如果一个节点标记为 Taints ,除非 Pod 也被标识为可以容忍污点节点,否则该 Taints 节点不会被调度Pod。
Taints(污点)是Node的一个属性,设置了Taints(污点)后,因为有了污点,所以Kubernetes是不会将Pod调度到这个Node上的。于是Kubernetes就给Pod设置了个属性Tolerations(容忍),只要Pod能够容忍Node上的污点,那么Kubernetes就会忽略Node上的污点,就能够(不是必须)把Pod调度过去。
Taints和Tolerations用于保证Pod不被调度到不合适的Node.上,其中Taint应用于Node上,而Toleration则应用于Pod上。
目前支持的Taint类型:
- NoSchedule:新的Pod不调度到该Node.上,不影响正在运行的Pod;
- PreferNoSchedule: soft版的NoSchedule, 尽量不调度到该Node上;
- NoExecute: 新的Pod不调度到该Node上,并且删除(evict) 已在运行的Pod。Pod可以增加一个时间(tolerationSeconds) 。
然而,当Pod的Tolerations匹配Node的所有Taints的时候可以调度到该Node上;当Pod是已经运行的时候,也不会被删除(evicted) 。另外对于NoExecute,如果Pod增加了一个tolerationSeconds,则会在该时间之后才删除pod。
比如用户希望把 Master 节点保留给 Kubernetes 系统组件使用,或者把一组具有特殊资源预留给某些 Pod,则污点就很有用了,Pod 不会再被调度到 taint 标记过的节点。taint 标记节点举例如下:
设置污点:
```yaml
$ kubectl taint node [node_name] key=value:[effect]
其中[effect] 可取值: [ NoSchedule | PreferNoSchedule | NoExecute ]
NoSchedule:一定不能被调度。
PreferNoSchedule:尽量不要调度。
NoExecute:不仅不会调度,还会驱逐Node上已有的Pod。
示例:kubectl taint node k8s-master smoke=true:NoSchedule
```
去除污点:
```yaml
去除指定key及其effect:
kubectl taint nodes [node_name] key:[effect]- #这里的key不用指定value
去除指定key所有的effect:
kubectl taint nodes node_name key-
示例:
kubectl taint node k8s-master smoke=true:NoSchedule
kubectl taint node k8s-master smoke:NoExecute-
kubectl taint node k8s-master smoke-
```
污点演示:
```yaml
## 给k8s-slave1打上污点,smoke=true:NoSchedule
$ kubectl taint node k8s-slave1 smoke=true:NoSchedule
$ kubectl taint node k8s-slave2 drunk=true:NoSchedule
## 扩容myblog的Pod,观察新Pod的调度情况
$ kuebctl -n demo scale deploy myblog --replicas=3
$ kubectl -n demo get po -w ## pending
```
Pod容忍污点示例:`myblog/deployment/deploy-myblog-taint.yaml`
```yaml
...
spec:
containers:
- name: demo
image: 172.21.32.6:5000/demo/myblog
tolerations: #设置容忍性
- key: "smoke"
operator: "Equal" #如果操作符为Exists,那么value属性可省略,不指定operator,默认为Equal
value: "true"
effect: "NoSchedule"
- key: "drunk"
operator: "Equal" #如果操作符为Exists,那么value属性可省略,不指定operator,默认为Equal
value: "true"
effect: "NoSchedule"
#意思是这个Pod要容忍的有污点的Node的key是smoke Equal true,效果是NoSchedule,
#tolerations属性下各值必须使用引号,容忍的值都是设置Node的taints时给的值。
```
## 调度优先级
从v1.8开始,kube-scheduler支持定义Pod的优先级,从而保证高优先级的Pod优先调度。开启方
法为:
- apiserver配置`--feature-gates=PodPriority=true`和`--runtime-config=scheduling.k8s.io/v1alpha1=true`
- kube-scheduler配置`--feature-gates=PodPriority=true`
### PriorityClass
在指定pod优先级之前先定义一个PriorityClass(非namespace资源),如:
```yaml
apiVersion: V1
Kind: PriorityClass
metadata:
name: high-priority
value: 1000000
globalDefault: false
description: "This priority class should be used for XYZ service pods only."
```
### 为pod设置priority
```yaml
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
env: test
spec:
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
priorityClassName: high-priority
```
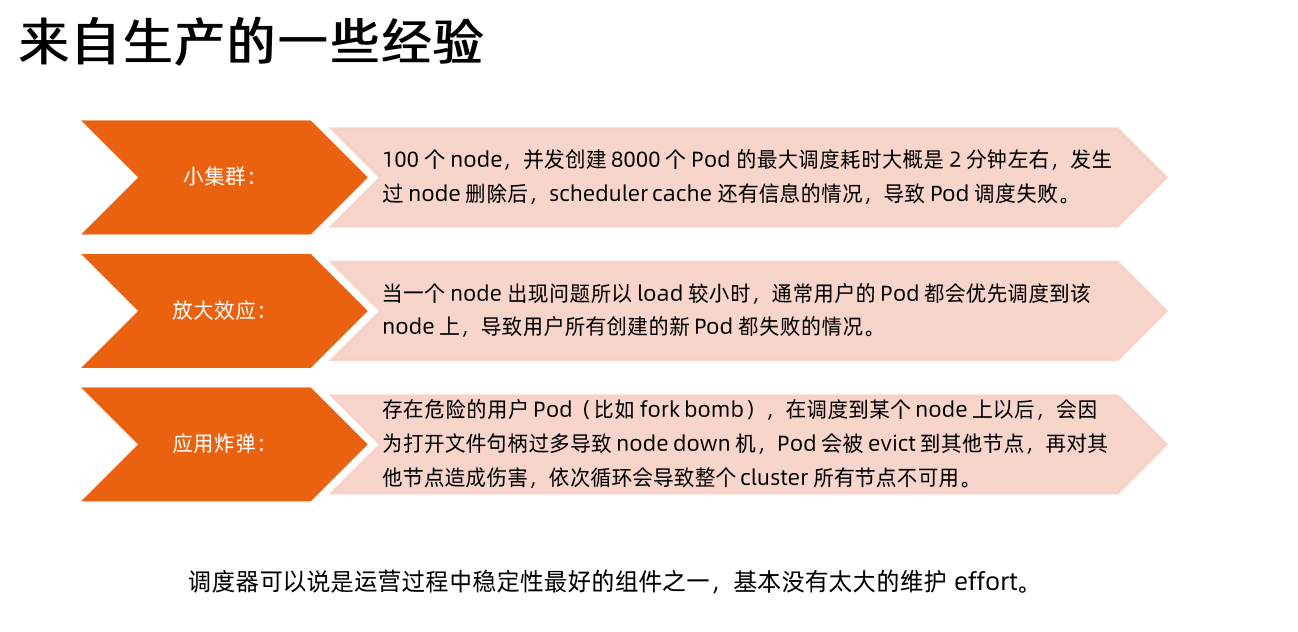
## 多调度器
如果默认的调度器不满足要求,还可以部署自定义的调度器。并且,在整个集群中还可以同时运行多个调度器实例,通过pod.Spec.schedulerName来选择使用哪-个调度器( 默认使用内置的调度器)。
## pod的nodeName指定
```yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-example
labels:
app: nginx
spec:
nodeName: k8s-node2 # 直接分配
containers:
- name: nginx
image: nginx:1.15
```
## kube-scheduler 代码走读
`https://cncamp.notion.site/kube-scheduler-0d45b37a5c9a46008aaf9f9e2088b3ce`
```golang
// Framework manages the set of plugins in use by the scheduling framework.
// Configured plugins are called at specified points in a scheduling context.
type Framework interface {
Handle
QueueSortFunc() LessFunc
RunPreFilterPlugins(ctx context.Context, state *CycleState, pod *v1.Pod) *Status
RunPostFilterPlugins(ctx context.Context, state *CycleState, pod *v1.Pod, filteredNodeStatusMap NodeToStatusMap) (*PostFilterResult, *Status)
RunPreBindPlugins(ctx context.Context, state *CycleState, pod *v1.Pod, nodeName string) *Status
RunPostBindPlugins(ctx context.Context, state *CycleState, pod *v1.Pod, nodeName string)
RunReservePluginsReserve(ctx context.Context, state *CycleState, pod *v1.Pod, nodeName string) *Status
RunReservePluginsUnreserve(ctx context.Context, state *CycleState, pod *v1.Pod, nodeName string)
RunPermitPlugins(ctx context.Context, state *CycleState, pod *v1.Pod, nodeName string) *Status
WaitOnPermit(ctx context.Context, pod *v1.Pod) *Status
RunBindPlugins(ctx context.Context, state *CycleState, pod *v1.Pod, nodeName string) *Status
HasFilterPlugins() bool
HasPostFilterPlugins() bool
HasScorePlugins() bool
ListPlugins() *config.Plugins
ProfileName() string
}
Schedule()-->
// filter
g.findNodesThatFitPod(ctx, extenders, fwk, state, pod)-->
// 1.filter预处理阶段:遍历pod的所有initcontainer和主container,计算pod的总资源需求
s := fwk.RunPreFilterPlugins(ctx, state, pod) // e.g. computePodResourceRequest
// 2. filter阶段,遍历所有节点,过滤掉不符合资源需求的节点
g.findNodesThatPassFilters(ctx, fwk, state, pod, diagnosis, allNodes)-->
fwk.RunFilterPluginsWithNominatedPods(ctx, state, pod, nodeInfo)-->
s, err := getPreFilterState(cycleState)
insufficientResources := fitsRequest(s, nodeInfo, f.ignoredResources, f.ignoredResourceGroups)
// 3. 处理扩展plugin
findNodesThatPassExtenders(extenders, pod, feasibleNodes, diagnosis.NodeToStatusMap)
// score
prioritizeNodes(ctx, extenders, fwk, state, pod, feasibleNodes)-->
// 4. score,比如处理弱亲和性,将preferredAffinity语法进行解析
fwk.RunPreScorePlugins(ctx, state, pod, nodes) // e.g. nodeAffinity
fwk.RunScorePlugins(ctx, state, pod, nodes)-->
// 5. 为节点打分
f.runScorePlugin(ctx, pl, state, pod, nodeName) // e.g. noderesource fit
// 6. 处理扩展plugin
extenders[extIndex].Prioritize(pod, nodes)
// 7.选择节点
g.selectHost(priorityList)
sched.assume(assumedPod, scheduleResult.SuggestedHost)-->
// 8.假定选中pod
sched.SchedulerCache.AssumePod(assumed)-->
fwk.RunReservePluginsReserve(schedulingCycleCtx, state, assumedPod, scheduleResult.SuggestedHost)-->
f.runReservePluginReserve(ctx, pl, state, pod, nodeName) // e.g. bindVolume。其实还没大用
runPermitStatus := fwk.RunPermitPlugins(schedulingCycleCtx, state, assumedPod, scheduleResult.SuggestedHost)-->
f.runPermitPlugin(ctx, pl, state, pod, nodeName) // empty hook
fwk.RunPreBindPlugins(bindingCycleCtx, state, assumedPod, scheduleResult.SuggestedHost) // 同 runReservePluginReserve
// bind
// 9.绑定pod
sched.bind(bindingCycleCtx, fwk, assumedPod, scheduleResult.SuggestedHost, state)-->
f.runBindPlugin(ctx, bp, state, pod, nodeName)-->
b.handle.ClientSet().CoreV1().Pods(binding.Namespace).Bind(ctx, binding, metav1.CreateOptions{})-->
return c.client.Post().Namespace(c.ns).Resource("pods").Name(binding.Name).VersionedParams(&opts, scheme.ParameterCodec).SubResource("binding").Body(binding).Do(ctx).Error()
```