弹性伸缩
# 弹性伸缩
## 传统弹性伸缩的困境
从传统意义上,弹性伸缩主要解决的问题是容量规划与实际负载的矛盾
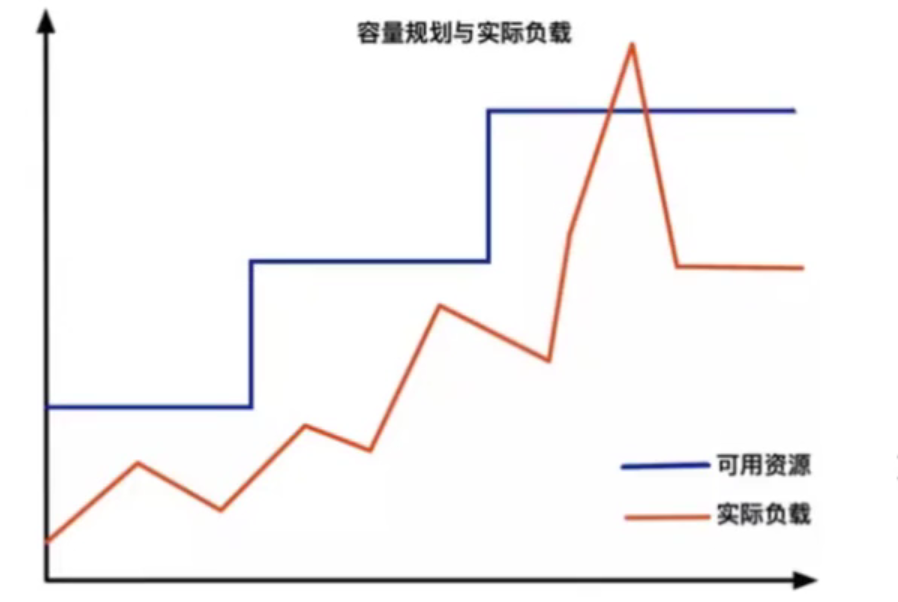
蓝色水位线表示集群资源容量随着负载的增加不断扩容,红色曲线表示集群资源实际负载变化。弹性伸缩就是要解决当实际负载增大,而集群资源容量没来得及反应的问题。
### 1、Kubernetes中弹性伸缩存在的问题
常规的做法是给集群资源预留保障集群可用,通常20%左右。这种方式看似没什么问题,但放到Kubernetes中,就会发现如下2个问题。
1.机器规格不统一造成机器利用率百分比碎片化
在一个Kubernetes集群中,通常不只包含一种规格的机器,假设集群中存在4C8G与16C32G两种规格的机器,对于10%的资源预留,这两种规格代表的意义是完全不同的。
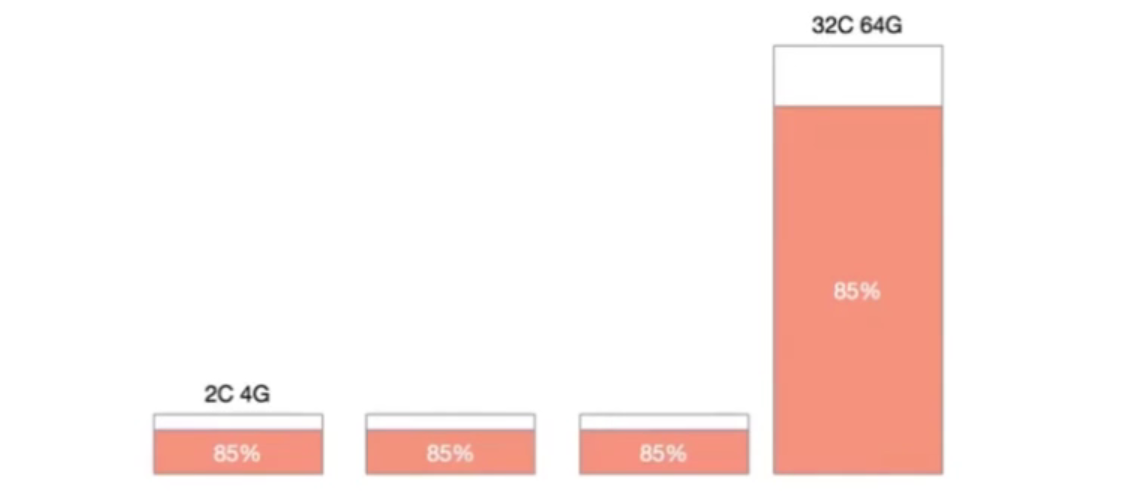
特别是在缩容的场景下,为了保证缩容后集群稳定性,我们一般会一个节点一个节点从集群中摘除,那么如何判断节点是否可以摘除其利用率百分比就是重要的指标。此时如果大规则机器有较低的利用率被判断缩容,那么很有可能会造成节点缩容后,容器重新调度后的争抢。如果优先缩容小规则机器,则可能造成缩容后资源的大量冗余。
2.机器利用率不单纯依靠宿主机计算
在大部分生产环境中,资源利用率都不会保持一个高的水位,但从调度来讲,调度应该保持一个比较高的水位,这样才能保障集群稳定性,又不过多浪费资源
### 2、弹性伸缩概念的延伸
不是所有的业务都存在峰值流量,越来越细分的业务形态带来更多成本节省和可用性之间的跳转。
1. 在线负载型:微服务、网站、API
2. 离线任务型:离线计算、机器学习
3. 定时任务型:定时批量计算
不同类型的负载对于弹性伸缩的要求有所不同,在线负载对弹出时间敏感,离线任务对价格敏感,定时任务对调度敏感。
## kubernetes弹性伸缩布局
在Kubernetes的生态中,在多个维度、多个层次提供了不同的组件来满足不同的伸缩场景。有三种弹性伸缩:
* CA (Cluster Autoscaler) : Node级别自动扩/缩容cluster-autoscaler组件
* HPA (Horizontal Pod Autoscaler) : Pod个数自动扩/缩容
* VPA (Vertical Pod Autoscaler) : Pod配置自动扩缩容,主要是CPU、内存addon-resizer组件(较为鸡肋,pod扩缩容时会重启,可能会对正在进行的业务产生影响,这样显然很不合理)
如果在云上建议HPA结合cluster-autoscaler的方式进行集群的弹性伸缩管理。
## Node自动扩容/缩容
1、cluster AutoScaler
扩容: Cluster AutoScaler定期检测是否有充足的资源来调度新创建的Pod,当资源不足时会调用CloudProvider创建新的Node。
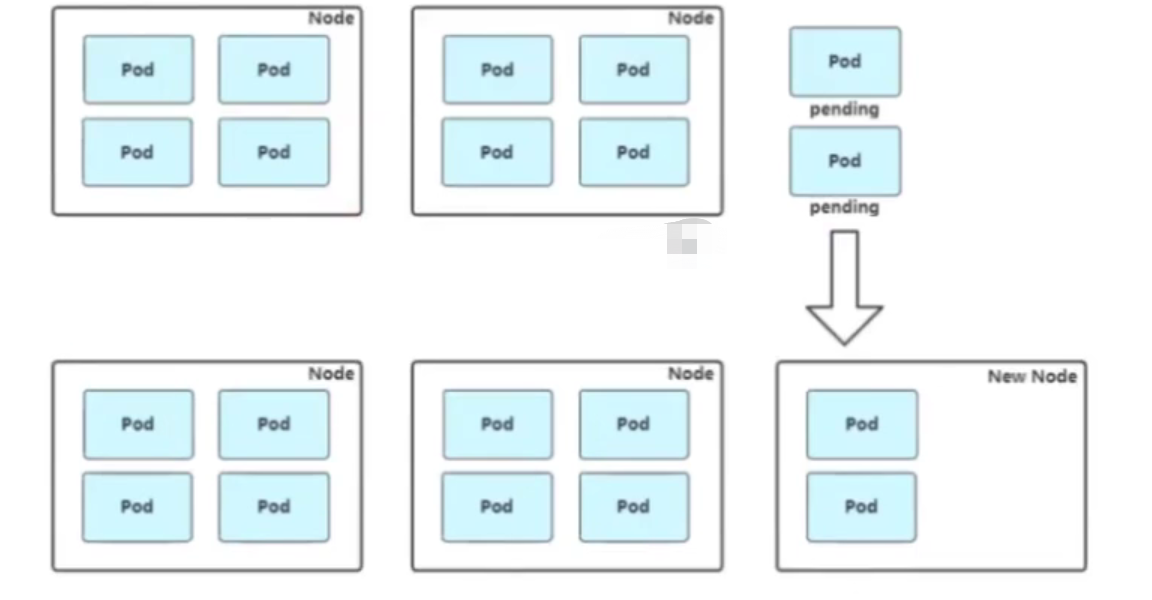
缩容:cluster AutoScaler也会定期监测Node 的资源使用情况,当一个Node 长时间资源利用率都很低时(低于50%)自动将其所在虚拟机从云服务商中删除。此时,原来的Pod会自动调度到其他Node上面。
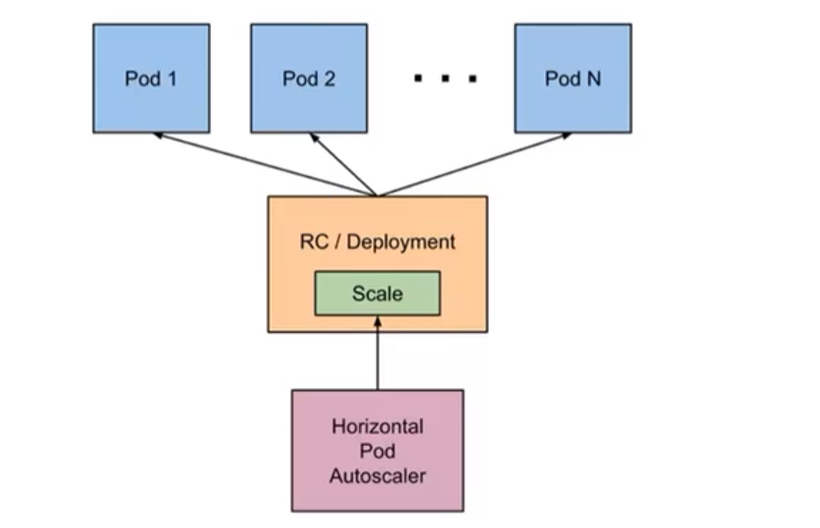
## Pod自动扩容/缩容(HPA)
Horizontal Pod Autoscaler (HPA,Pod水平自动伸缩),根据资源利用率或者自定义指标自动河整replicationcontroller, deployment或 replica set,实现部署的自动扩展和缩减,让部署的规模接近于实际服务的负载。HPA不适于无法缩放的对象,例如DaemonSet。
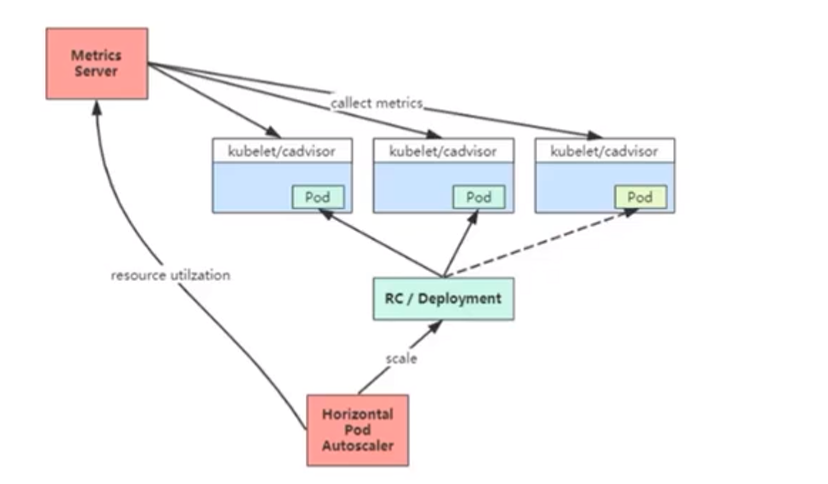
### 1、HPA基本原理
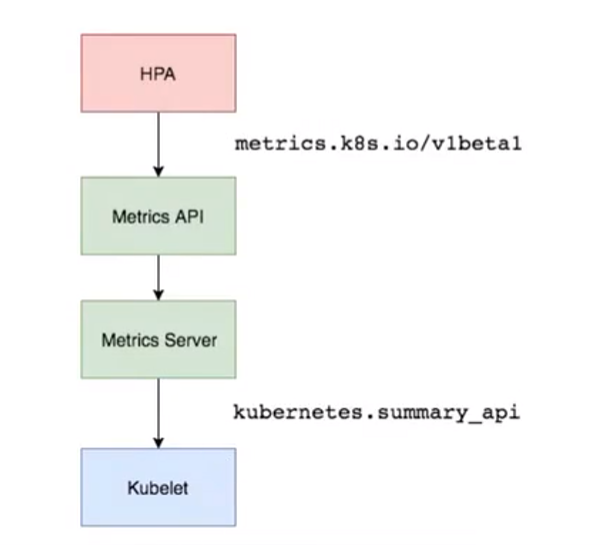
Kubernetes 中的Metrics Server持续采集所有Pod副本的指标数据。HPA 控制器通过Metrics Server的API(Heapster的API或聚合API,早期版本,现已弃用,使用Metrics Server,cadvisor采集容器资源利用率)获取这些数据,基于用户定义的扩缩容规则进行计算,得到目标Pod副本数量。当目标Pod副本数量与当前副本数量不同时,HPA 控制器就向Pod的副本控制器(Deployment、RC或ReplicaSet)发起scale操f作,调整Pod的副本数量,完成扩缩容操f作。如图所示。
HPA 原理: HPA Controller默认30s轮询一次,查询指定的资源中的 Pod 资源使用率,并且与创建时设定的值和指标做对比情况来确定是否需要调整 Pod 的副本数量,从而实现自动伸缩的功能。
Kubernetes 项目中的一个通用编排模式,即:控制循环(control loop)。
```
for {
desired := getDesiredState() // 期望的状态
current := getCurrentState() // 当前实际状态
if current == desired { // 如果状态一致则什么都不做
// nothing to do
} else { // 如果状态不一致则调整编排,到一致为止
// change current to desired status
}
}
```
在弹性伸缩中,冷却周期是不能逃避的一个话题,由于评估的度量标准是动态特性,副本的数量可能会不断波动。有时被称为颠簸,所以在每次做出扩容缩容后,冷却时间是多少。
在HPA中,默认的扩容冷却周期是3分钟,缩容冷却周期是5分钟。
可以通过调整kube-controller-manager组件启动参数设置冷却时间:
扩容冷却: `--horizontal-pod-autoscaler-downscale-delay`
缩容冷却: `--horizontal-pod-autoscaler-upscale-delay`
### 2、HPA的演进历程
目前HPA已经支持了autoscaling/v1、autoscaling/v2beta1和autoscaling/v2beta2三个大版本。目前大多数人比较熟悉是autoscaling/v1,这个版本只支持CPU一个指标的弹性伸缩。
而autoscaling/v1beta1增加了支持自定义指标,autoscaling/v1beta2又额外增加了外部指标支持。
而产生这些变化不得不提的是Kubernetes社区对监控与监控指标的认识认识与转变。从早期Heapster到MetricsServer再到将指标边界进行划分,一直在丰富监控生态。
[官网Pod 水平自动扩缩](https://kubernetes.io/zh-cn/docs/tasks/run-application/horizontal-pod-autoscale/)
## 基于CPU指标缩放
1、Kubernetes API Aggregation
在Kubernetes 1.7版本引入了聚合层,允许第三方应用程序通过将自己注册到kube-apiserver上,仍然通过APIServer的HTTP URL对新的API进行访问和操作。为了实现这个机制,Kubernetes在kube-apiserver服务中引入了一个API聚合层(API Aggregation Layer),用于将扩展API的访问请求转发到用户服务的功能。
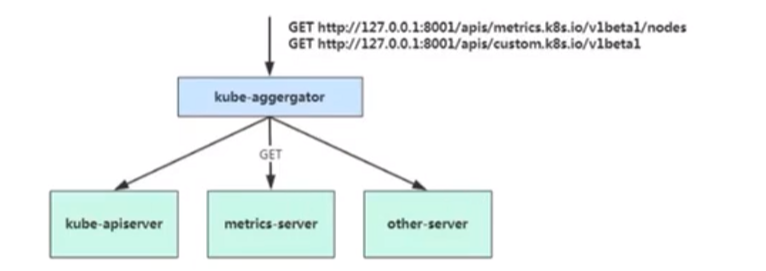
当你访问apis/metrics.k8s.io/v1beta1的时候,实际上访问到的是一个叫作kube-aggregator的代理。而kube-apiserver,正是这个代理的一个后端;而Metrics Server,则是另一个后端。通过这种方式,我们就可以很方便地扩展Kubernetes的API了。
如果你使用kubeadm部署的,默认已开启。如果你使用二进制方式部署的话,需要在kube-APIServer中添加启动参数,在设置完成重启kube-apiserver服务,就启用API聚合功能了。
2、部署Metrics Server
Metrics Server是一个集胖范围的资源使用情况的数据聚合器。作为一个应用部署在集群中。Metric server从每个节点上Kubelet公开的摘要API收集指标。
Metrics server译过Kubernetes聚合器注册在MasterAPIServer中