深入浅出数据分析
# 1. 引言——分解数据
**要点:**
**1)数据分析固定流程**(四步)
确定(问题)-> 分解(问题和数据) -> 评估(分析,作出结论) -> 决策(建议)
**2)心智模型:**
你对外界的假设和你确信的观点,帮助你理解现实世界,而统计模型取决于心智模型。
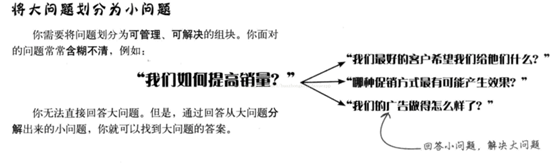
**案例:**
公司想提高销量,通过发现老年男子这个消费群体并针对其营销,提升了Acme化妆品公司销量。
::: hljs-center
:::
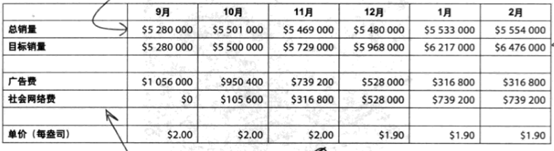
**数据:**
::: hljs-center
:::
针对数据,再结合对公司业务的了解,做出了如下的数据分析报告:
::: hljs-center

:::
但通过数据没有体现少女消费者市场的任何情况。他假定少女消费者是产品唯一购买者,而且少女消费者有能力购买更多的貌洁保湿霜。
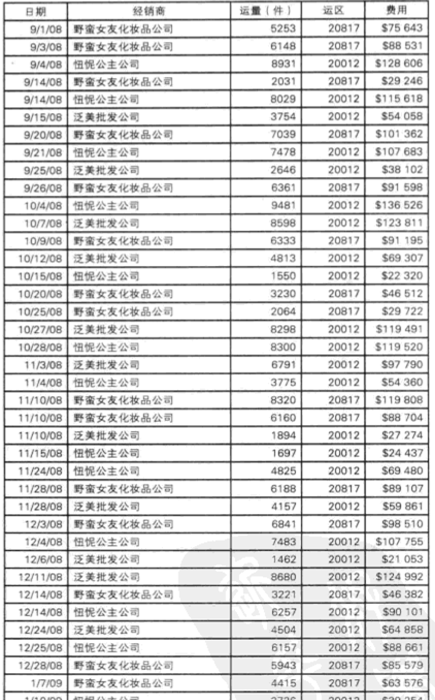
于是乎,我们得到了其它的数据,关于貌洁保湿霜经销商的销售数据,如下图:
::: hljs-center
:::
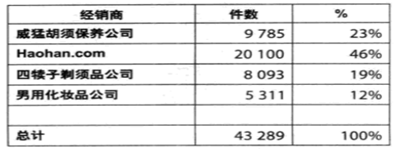
从中我们深入挖掘数据,任务很明确,找出除少女消费者以外购买产品的群体,从中我们发现了一家泛美批发公司,得到了它貌洁保湿霜半年的销售明细(至2009年2月),如图:
::: hljs-center
:::
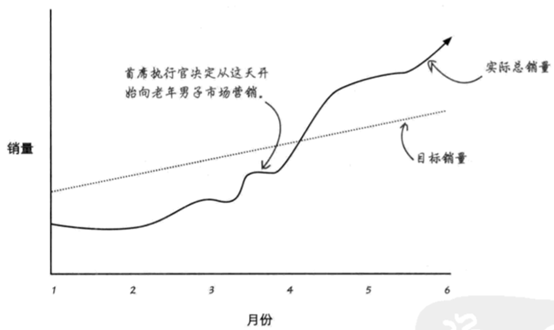
看来有男人群体也在买貌洁保湿霜,而公司并未意识到,一切顺利的话就靠这个潜在群体提高销量了。
于是,公司迅速调动营销团队创建“须洁”品牌——无非就是“貌洁”保湿霜换个名字罢了,下图为结果:
::: hljs-center
:::
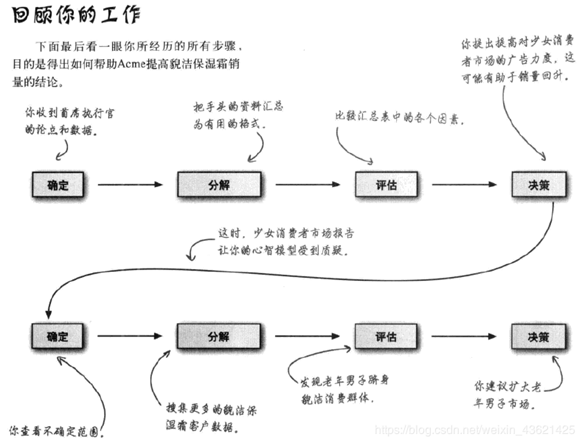
**回顾:**
::: hljs-center
:::
案例中开始作出调整广告的建议,但是中间收看到一个产品针对少女市场饱和的新闻。那么合理建议一下子被否定了。那么就需要重新开始进行**确定->分解->评估->决策。**
最后通过不断的分解和假设到掌握真实的边缘信息,深入挖掘市场数据得到新的目标客户发现有男士使用该产品,最后得出推出新男士品牌的决策,提高销量达到客户要求。
# 2. 实验——检验你的理论
本章主要介绍一定要用实验来校验自己对数据分析产生的结论。
**以咖啡咖啡销量为背景:**
**1,观察数据要考虑到混杂因素,并列举出来**
选址方便、咖啡温度、员工热情、咖啡价值、偏爱去处
**2,拆分数据块,管理混杂因素**
东安地区分店、西雅图区分店、SOHO区分店
**3,实验必须加入实验组和控制组**
为什么要加入控制组? 因为在第一次试验中,有降价和向客户说服咖啡是有价值的两条建议,但是实验只采取了降价措施,并没有说服价值行动,这样就会受到降价是否有效的质疑,所以最终建立了降价和说服两个实验组和一个默认控制组,从而可以进行最后的比较。故以控制组为基准才可以证实实验对应的假设条件是否有效。其中,也讲到了随机选择相似组的方法和重要性。
**最后的整个流程就是:**
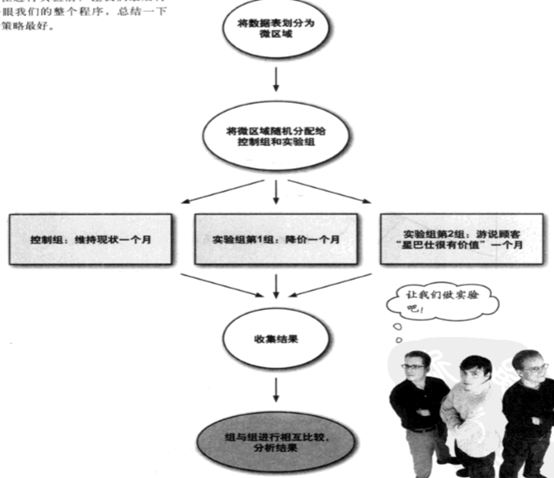
将数据表划分为微区域->将微区域随机分配给控制组和实验组->进行实验观察->收集结果->组与组进行相互比较,分析结果。
**要点:**
1)比较法:数据只有通过相互比较才会有意义。比较越多,分析结果越正确。
2)观察研究法:被研究的人自行决定自己属于哪个群体的研究方法。
3)混杂因素:研究对象的个人差异,会降低分析结果的敏感度。
4)控制组(对照组):一组体现现状的处理对象,未经过任何新的处理,用于和实验组进行比较。
**检验你的理论**
**案例:**
经过随机控制实验,发现可以通过游说人们星巴仕咖啡有价值,恢复该咖啡店的销量。
咖啡业的寒冬到了,连星巴仕咖啡店也在经历剧痛,在过去几个月里,实际销量与目标销量背道而驰,骤然下降。如下图:
::: hljs-center

:::
市场部每个月会做一次客户调查,会对大量客户进行抽样调查,如下图的调查表
::: hljs-center

:::
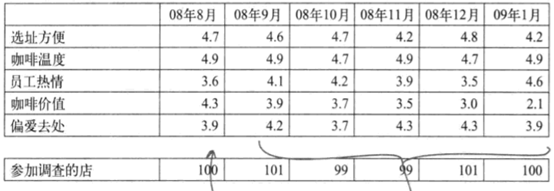
下图为2008年下半年市场调查汇总表,表中数字是各家分店参加调查的人对各个调查项给出的平均分:
::: hljs-center
:::
纵观这些数据,除了星巴仕咖啡价值这个变量,顾客对其他方面都感觉良好;看起来,星巴仕没有给人们物超所值的感觉,这可能是导致购买下降的原因。SoHo是一个富人区,也是几家利润丰厚的星巴仕分店的所在地,负责这几家分店的经理不相信这个问题的存在。
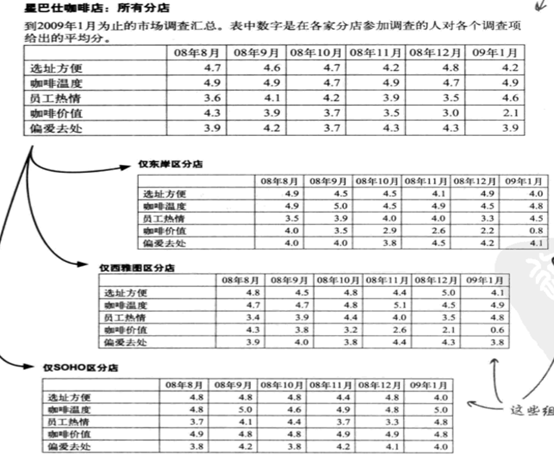
混杂因素就是研究对象的个人差异,它们不是你视图进行比较的因素,最终会导致分析结果的敏感度变差。上述案例的混杂因素是店址,我们需要将SoHo和其它分店分开,校正选址混杂因素。
接下来我们拆分数据块,管理混杂因素。下面我们再来看看星巴仕的调查数据,这一次将其它地区的数据列在相应的表格里。
::: hljs-center
:::
在首席财务官的提示下,所以星巴仕分店的咖啡价格统统降低0.25美元,如下为销量情况
::: hljs-center
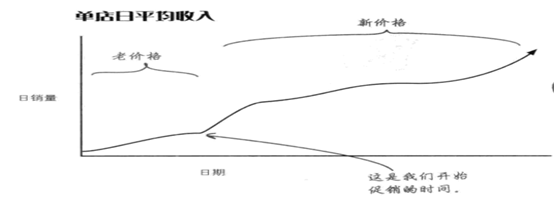
:::
通过这个数据我们能知道星巴仕2月份降价比不降价多赚了多少吗?显示不能。因为销量数据都是来自3.75美元的咖啡售价,无法与假定数据——也就是4.00美元的咖啡售价产生的销售收入进行比较。这违背了比较法,好的是实验总是有一个控制组(对照组)
::: hljs-center
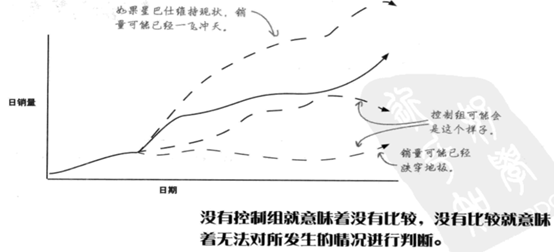
:::
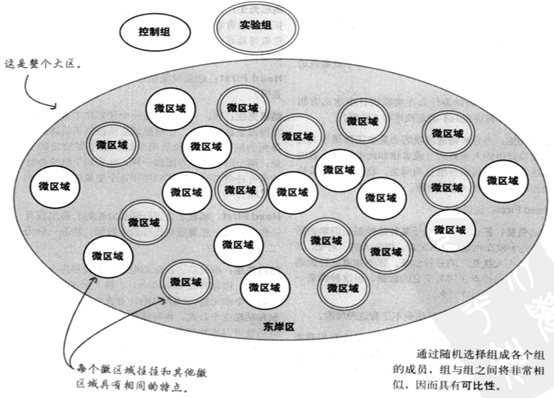
让我们重新做一次实验,这一次把所有星巴仕分店分成了控制组和实验组;实验组包括太平洋区所有分店,控制组包括SoHo区和东岸区所有分店
::: hljs-center
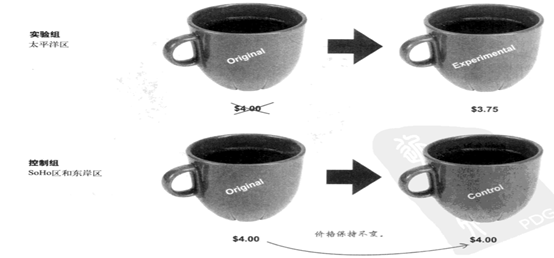
:::
一个月后,你得到了下面的图
::: hljs-center
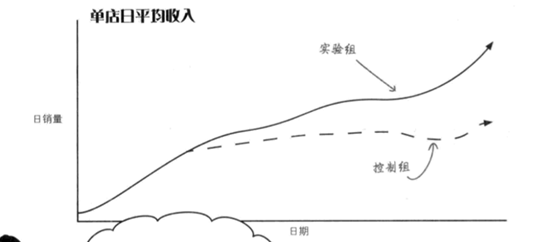
:::
有混杂因素吗?有的
::: hljs-center

:::
经过我们的思考,我们想到了四种分组方法,我们可以思考看看哪种分组比较适合
::: hljs-center

:::
我们决定采用最后一个分组方法
::: hljs-center
:::
在进行实验前,让我们最后再看一眼我们的整个程序,总结一下哪个策略最好。
::: hljs-center
:::
结果在此,与其它两个组相比,价值游说组的日营业收入立即上升,而降价组的营业收入其实是与控制组持平。
::: hljs-center
约束条件**:限制要优化变量(如利润)的考虑事项,告诉你在实现最大化的过程中无法做的事。
**2)决策变量**:你能控制的变量。
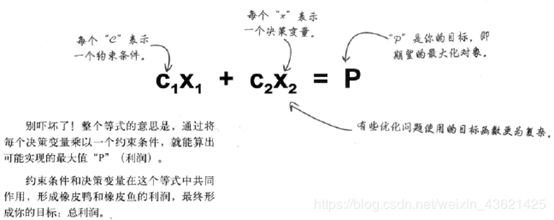
**3)最优化问题**:通过改变决策变量,得到某一目标的最大值或最小值。以下为一种目标函数:
::: hljs-center
:::
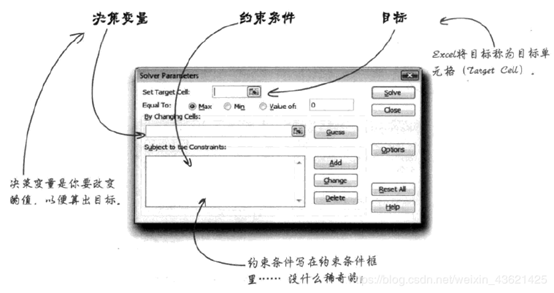
**4)使用Excel中的Solver(规划求解)实现最优化。**
::: hljs-center
:::
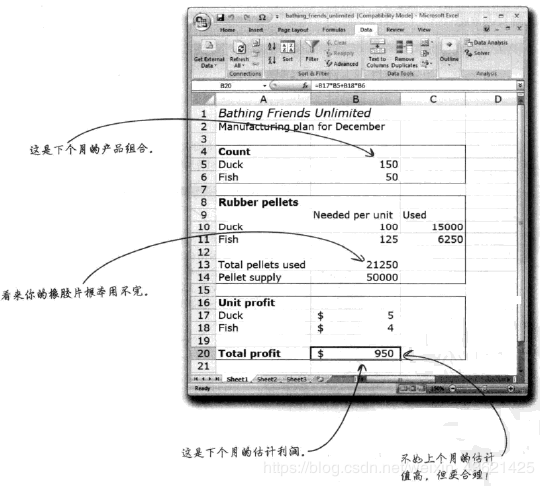
**案例:**
根据销售变化规律和生产限制条件,以最大化利润为目标,建议了合适的橡皮鸭和橡皮鱼生产组合,让浴盆宝公司获得了最大盈利。
::: hljs-center
:::
**总结**:
**1、变量因子受到的限制条件:**
厂家有多少橡胶用来生产这些产品、厂家生产这两类产品需要多长时间?
**2、借助目标函数来发现目标 $C_{1} X_{1}+{{C}}_{2} X_{2}={P}$**
$C$表示约束条件、$X$表示决策变量、$P$是你的目标
那么$C_{1} X_{1}$表示橡皮鸭利润、$C_{2} X_{3}$表示橡皮鱼利润,$P$就是总利润
$C$可以表示每个产品的利润,$X$可以表示产品的数量,$CX$就表示总利润了。
**3、确定合理的选择区**
规定的时间内,最多只能生产400只橡皮鸭和300条橡皮鱼。
根据橡胶的供应量,只能生产500只橡皮鸭,或者400条橡皮鱼。
画出对应的选择区域利用Excel中的Solver工具进行求解。
**4、结果实际利润中发现通过1,2,3步骤得出的结论是错误的**
因为你的模型只是描述了你规定的情况,于是找出历史数据进行具体的分析
发现每个月的销售数量和利润随着月份在波动。
**5、提防负相关变量**
通过折线图可以发现,一个产品越多,另一个产品就越少,并且折线图可以反映每个月的波动情况。
于是改变约束条件,即下个月的销售数量的最大值从折线图来看不会超过多少来增加限制,从而得出最优解。最终得出有效的解决方案。
# 4. 数据图形化——图形让你更精明
本章主要讲解是如何让数据图形化,这里就不是简单的利用Excel自带的一些表格来绘制图形,而是开始讲到用R语言来绘制。
1,数据图形化的根本在于正确比较
2,使用散点图探索原因
3,最优秀的图形是多元图形
4,同时展示多张图形,体现更多变量
**总结:**
这张主要就是讲解要学会从大量数据中筛选有用的数据(不是所有的数据都是有效的),然后将数据图形化的时候不是之前章节简单的折线图或者直方图或者线性图,而是离散且多变量图形的展示,便开始引出R语言来将数据可视化的概念。而不是简单的Excel图形工具。
# 5. 假设验证——假设并非如此
**要点:**
**1)假设验证:** 用伪证法剔除无法证实的假设,再用诊断性证据评估和判定各种假设的相对强度。
**2)诊断性**:证据所具有的一种功能,能够帮助你评估所考虑的假设的相对似然(likelihood)。如果证据具有诊断性,就能帮助你对假设排序。
1. **问题**
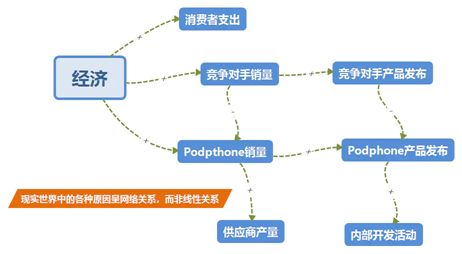
电肤公司是一家手机“皮肤”制造商。手机巨头Podphone公司即将发布一款手机,时间待定。电肤公司必须在手机发布前的一个月开始生产手机皮肤,才能赶上手机销售的第一波。当前的任务是电肤公司何时生产新手机皮肤?
2. **搜集证据**
通过搜集产品发布信息,梳理这些信息中体现的变量关系,分为正相关和负相关关系。
::: hljs-center
:::
3. **提出假设**
::: hljs-center

:::
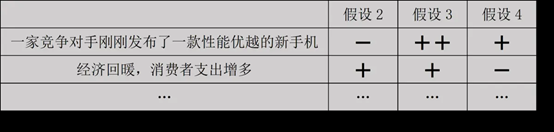
4. **假设检验**
1)假设检验的核心是证伪,即剔除无法证实的假设,排除错误假设。
根据资料可排除1和假设5
2)对于假设2-4,借助诊断法找出否定性最小的假设,判定哪个假设最强。
::: hljs-center
:::
得出假设3为最强假设
**3)新证据来了**:Podphone公司召开了新手机打样庆祝会,新证据使得假设2变为最强假设!
**4)根据最新分析结果采取行动吧!**
# 8.启发法——凭人类的天性做分析
**1. 问题**
邋遢集是由数据邦市市政府资助的一个非盈利团体,他们进行公开宣传,劝说人们不要乱扔垃圾。他们把最近的工作结果汇报给了市政府,但市政府需要知道垃圾量减少了多少,否则就会削减资金!
**2. 难题**
难题是垃圾量的减少无法定量计算出来,没有一个统一的散乱垃圾计量模型。垃圾的定量计算看似走不通。
**3. 方法**

**基于启发法的发散式思维**
人们以极快速度作出的决定或不凭借任何数据作出的决定,往往靠的是直觉,直觉一般看到的只有一个选项。**通过发散式思维的思考,即启发法,可以得出多个选项,进行分析得出最优解**。现在用启发法确定用哪些变量分析能够更全面地描述邋遢集的绩效。
::: hljs-center

:::
**基于启发法的邋遢集绩效描述变量确定**
站在市议员的角度考虑他们会如何评估邋遢集的工作,用启发法构思如下:
::: hljs-center

:::
**基于启发法的工作评估**
在利用启发法确定重要因素后,搜集数据,包括环卫工人问卷、公众问卷、站在议员角度可能会提问的答案等。给市议员一个定量的报告和回复。