流程
# 实验设计
AB Test 实验一般有 2 个目的:
**判断哪个更好**:例如,有 2 个 UI 设计,究竟是 A 更好一些,还是 B 更好一些,我们需要实验判定
**计算收益**:例如,最近新上线了一个直播功能,那么直播功能究竟给平台带了来多少额外的 DAU,多少额外的使用时长,多少直播以外的视频观看时长等
我们一般比较熟知的是上述第 1 个目的,对于第 2 个目的,对于收益的量化,计算 ROI,往往对数据分析师和管理者非常重要。
对于一般的 ABTest 实验,其实本质上就是把平台的流量均匀分为几个组,每个组添加不同的策略,然后根据这几个组的用户数据指标,例如:留存、人均观看时长、基础互动率等等核心指标,最终选择一个最好的组上线。
> **Q**:AB test背后的理论支撑是什么?
> **A**:中心极限定理和假设检验。
# 制定关注指标
**方法**:围绕业务制定实验中的核心关注指标(Driver Metrics),同时定义护栏指标(Guardrail Metrics)
**说明**:护栏指标的存在,是为了防止我们的策略发生“捡芝麻掉西瓜”的情况。当护栏指标显著负向的时候,就算核心关注指标显著正向,我们依然不建议推全实验
# 计算样本量
**方法**:围绕关注指标,用其历史数据计算最小样本量
**说明**:实验样本大于最小样本量的前提下,检验才有足够的“力量”检验到显著效果。最小样本量分析的英文名为:power analysis
计算最小样本量两种检验方法(在A/B Test中常见的检验方法为Z/t检验)
这里的最少样本量,指的是最少流量**实验组**的样本量
如果我们每天只有 5W 的用户可用于实验,而最小样本量为63w,63/ 5 = 13 天,我们需要至少 13 天才能够得到实验结论
---
**卡方检验**:检验实验组是否服从理论分布(将对照组的分布视为理论分布),适用范围:自变量因变量都是类型。适合比率等指标。
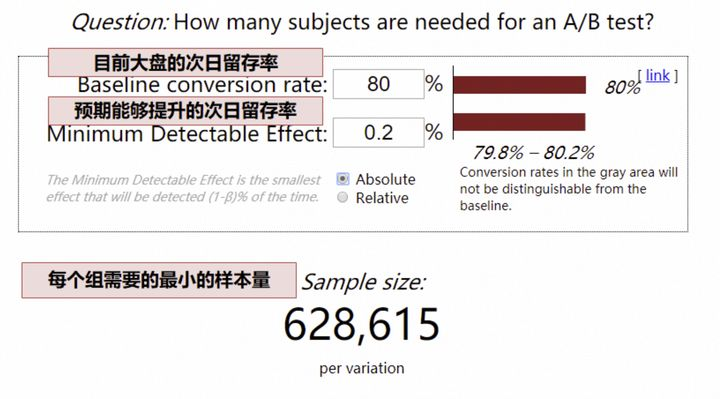
根据实验的预期结果,大盘用户量,确定实验所需最小流量,可以通过一个[网站](https://www.evanmiller.org/ab-testing/sample-size.html)专门计算所需样本量:
- 以次日留存率为例,目前大盘次日留存率 80%,预期实验能够提升 0.2pp(这里的留存率可以转换为点击率、渗透率等等,**只要是比例值就可以**,如果估不准,为了保证实验能够得到结果,此处可低估,不可高估,也就是 0.2pp 是预期能够提升地最小值)
- 网站计算,最少样本量就是 63W
- (这里的最少样本量,指的是最少流量实验组的样本量)
- 如果我们每天只有 5W 的用户可用于实验(5W 的用户,指最少流量实验组是 5W 用户),63/ 5 = 13 天,我们需要至少 13 天才能够得到实验结论
---
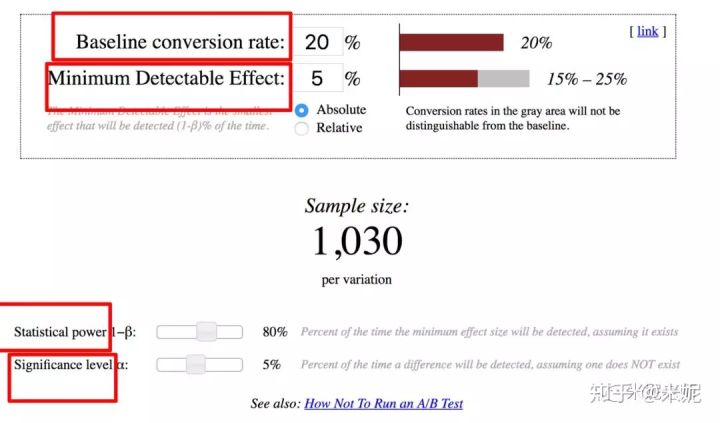
**Z/t检验**:检验实验组和对照组服从分布的均值是否相等
如果我们预期提升的指标是人均时长、人均 VV 等,可能就比较复杂了,我们需要运用 t 检验反算,需要的[做A/B实验需要多少样本?](doc:9uMbdkSn):
---
# 流量分配
**AB Test数据流**:APP启动时,公共框架会拉取所有线上ABTest的试验号和对应版本(所有BU)存入本地,当用户进入机票频道时候,在特定场景触发本地实验号调用。比如往返实验,在用户首页点击往返搜索时,开发会从本地文件中查询160519_fld_round试验号该用户的对应版本,确定跳转新/旧版页面。在试验号接收到调用时,同时触发一个ABTest的trace埋点o_abtest_expresult,该埋点会记录clientcode,sid,pvid,试验号及版本信息,最终经过ETL,BI会汇总一张AB实验表,将上述信息汇总,便于后续做关联计算。
**分流计算**:每个设备在刚启动的时候会根据设备号+试验号+随机数组成一串N位数,对100取模的余数从0-99,假设ABCD四个版本流量 10:70:10:10的情况下,则余数0-9为A版、10-79为B版、80-89为C版、90-99为D版。A版为默认版,如果尾数异常(Null或溢出),则走A版。
**AB版本**:如果仅有新旧两个版本的情况下,一般会设置ABCD四个版本,(其中ACD为旧版,B为新版;如果有多个迭代新版,则从EFG开始)来进行AA测试和AB测试。
1. **AA测试**:CD版同为旧版,且流量各为B版一半,在流量随机分配的情况,通过对比CD版的数据表现来验证旧版的状态是稳定的。A版作为旧版,也称为兜底版本,BCD的剩余流量走A版,版本异常的情况下走A版。在测试时首先要保证AA test能通过,确保分组的合理性,才能进行AB test,否则就没有意义。
2. **AB测试**:在确保CD数据相对稳定的前提下,再对比B和ACD版本的数据,来对比新旧版的差异。
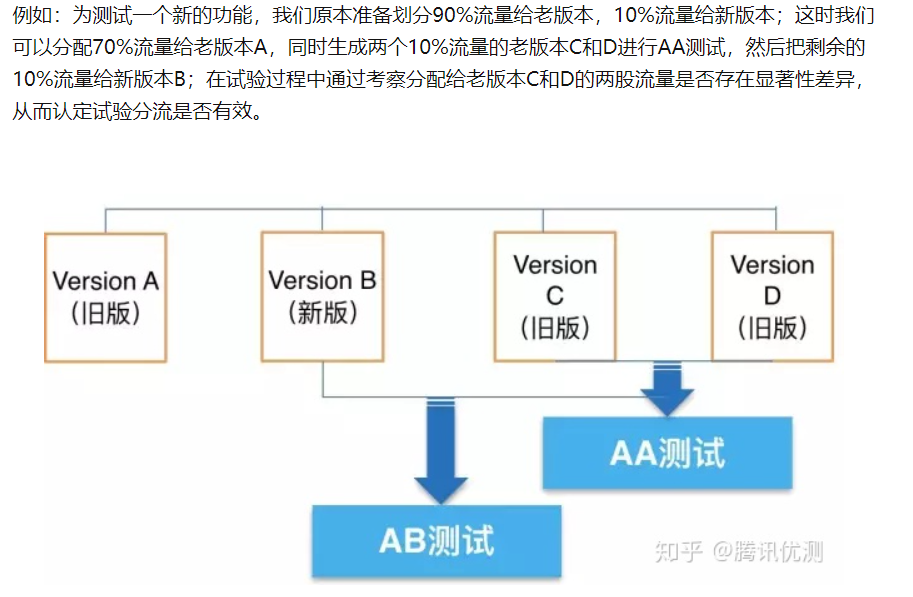
> AA和AB同时进行,给A的70%流量不动,相当于取30%做AB+AA。然后,对于分出来AA的组,若是没有显著差异,可以融合会对照组,但是知乎内部的做法是抛弃,一般要让AB实验组对照组的流量一致。
> 直到分配的这些流量的行为数据满足了最小样本数量要求,才可接着分析结论。例子[A/B测试(基础篇)](https://zhuanlan.zhihu.com/p/364723088):应用3。
> [怎么圈定哪些用户进行 A 实验,哪些用户进行 B 实验](https://yangwenbo.com/articles/abtest-traffic-diversion.html)。可以采用hash算法用自增ID来圈定用户,这样进行孤立实验可以,一份流量只能用来做一个测验。目前,业界提出了可重叠分层分桶方法。
具体来说,就是将流量分成可重叠的多个层。因为很多类实验从修改的系统参数到观察的产品指标都是不相关的,完全可以将实验分成互相独立的多个层。例如 UI 层、推荐算法层、广告算法层,或者开屏、首页、购物车、结算页等。
单单分层还不够,在每个层中需要使用不同的随机分桶算法,保证流量在不同层中是正交的。也就是说,一个用户在每个层中应该分到哪个桶里,是独立不相关的。具体来说,在上一层 001 桶的所有用户,理论上应该均匀地随机分布在下一层的 1000 个桶中。
通过可重叠的分层分桶方法,一份流量通过 N 个层可以同时中 N 个实验,而且实验之间相互不干扰,能显著提升流量利用率。
**实验设计时有两个目标**:
- 希望尽快得到实验结论,尽快决策
- 希望收益最大化,用户体验影响最小
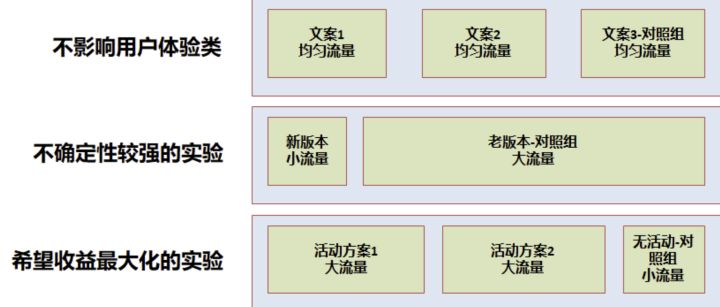
**因此经常需要在流量分配时有所权衡,一般有以下几个情况**:
- 不影响用户体验:如 UI 实验、文案类实验等,一般可以均匀分配流量实验,可以快速得到实验结论
- 不确定性较强的实验:如产品新功能上线,一般需小流量实验,尽量减小用户体验影响,在允许的时间内得到结论
- 希望收益最大化的实验:如运营活动等,尽可能将效果最大化,一般需要大流量实验,留出小部分对照组用于评估 ROI
# AA测试
> AA测试目的:1)测试埋点、分流、实验统计的正确性,增加AB实验的实验结论可信度;2)观察 观测指标在不做任何改动时的波动范围,如果波动范围比较大,那实验结果也很可能不置信
AA阶段检测组间差异
**方法**:在AB实验策略上线前,对已经分流好的实验组和对照组进行组间差异检验(如参数检验t-test,或者非参检验bootstrap):
- 当p-value > alpha(0.05)时,接受原假设(原假设H0:mean(a) = mean(b)),说明实验组和对照组组间无差异,可上线策略进行ab实验;
- 当p value < alpha(0.05)时,拒绝原假设,说明实验组和对照组组间有差异,这时候**可尝试的方法有**:
> 1. 参数检验过不了的话,可尝试非参检验
> 2. 增加样本量或者重开实验
> 2. 观测数据,是否有明显的outliers,考虑对其进行数据处理
> 3. 可考虑重新进行随机分流、也可考虑分层随机分流
> 4. 可考虑双重差分法 :[双重差分模型了解一下?](https://blog.csdn.net/junhongzhang/article/details/100179484)
# 实验结果
**需要回答几个问题**
1. 方案 1 和方案 2,哪个效果更好?
2. 长期来看哪个更好?
3. 不同群体有差异吗?
## 哪个方案效果更好?
**如何选择采用哪种假设检验?**
**Z检验**:一般用于大样本(即样本容量大于30)平均值差异性检验的方法。它是用标准正态分布的理论来推断差异发生的概率,从而比较两个平均数的差异是否显著。在国内也被称作u检验。
**T检验**:主要用于样本含量较小(例如n < 30),总体标准差σ未知的正态分布。T检验是用t分布理论来推论差异发生的概率,从而比较两个平均数的差异是否显著。
**卡方检验**:卡方检验是统计样本的实际观测值与理论推断值之间的偏离程度,实际观测值与理论推断值之间的偏离程度就决定卡方值的大小,如果卡方值越大,二者偏差程度越大;反之,二者偏差越小;若两个值完全相等时,卡方值就为0,表明理论值完全符合。例子:[如何通俗的理解A / B测试与卡方检验](https://zhuanlan.zhihu.com/p/145858910)

通过上假设检验,如果结论置信,我们就能够得到方案 1 和方案 2 在哪像指标更好(有显著性差异), 对于不置信的结论,尽管方案 1 和方案 2 的指标可能略有差异,但可能是数据正常波动产生。
对于留存率、渗透率等漏斗类指标,采用[卡方检验](https://www.evanmiller.org/ab-testing/chi-squared.html):

对于人均时长类等均值类指标,采用[t检验](https://www.evanmiller.org/ab-testing/t-test.html):
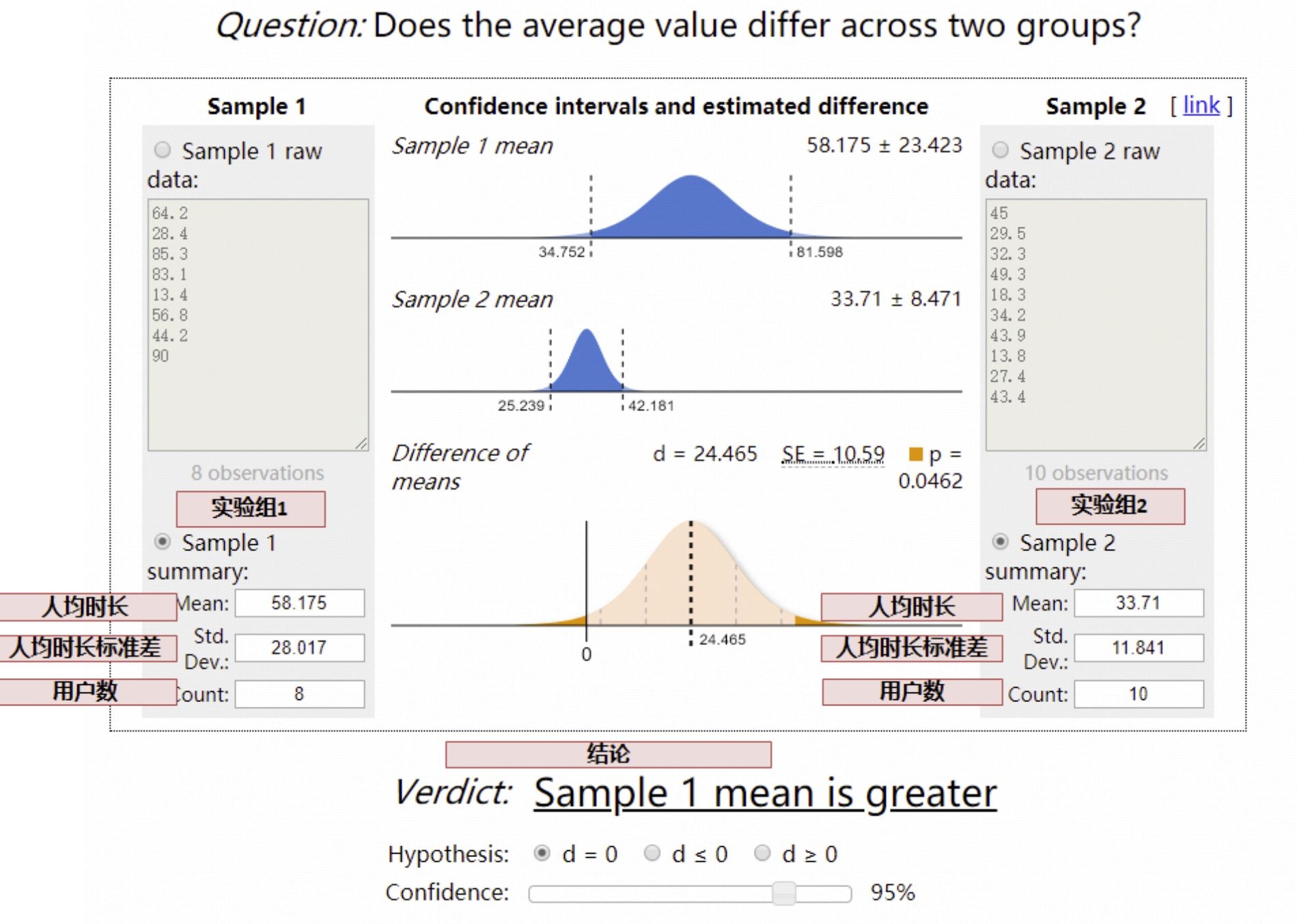
- 统计原理,用Z检验举例

## 长期来看哪个更好?
这里就要考虑新奇效应的问题了,一般在实验上线前期,用户因为新鲜感,效果可能都不错,因此在做评估的时候,需要观测指标到稳定态后,再做评估。
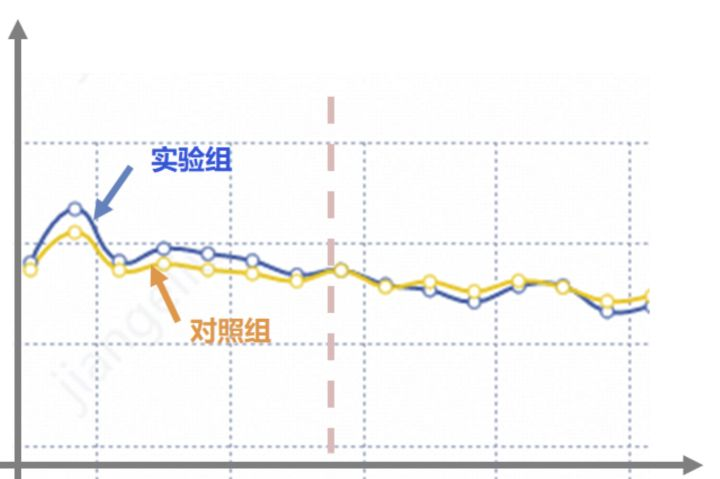
例如有的时候出现,刚刚上线前期,实验组效果更好,但是经过一段时间,用户的新鲜感过去了,实验组的效果可能更差,因此,从长远收益来看,我们应该选择对照组,是实验组的新奇效应欺骗了我们,在做实验分析时,应剔除新奇效应的部分,待平稳后,再做评估。
**如何看图表:**
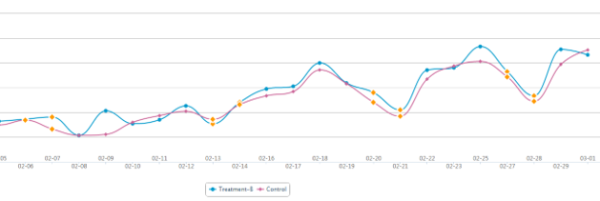
图表反映时间趋势,在ABTest中表现为新旧版本两条折线图,且一般会出现交叉的情况,那我们就需要判断这些交叉是有随机性波动还是实验的效果,我在实践中总结简单易用的一条原则是:“抓大放小”。
抓大放小(个别表现不影响整体趋势):当你遮住有限个点的时候,不影响整体的差异。比如下图,当你遮住2-11和2-13两天的数据时,会发现蓝色B版优于红色旧版。(当然遮住点的数量因人而异,一般不超过总量10%)
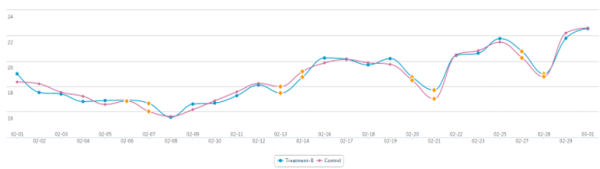
这张图就很难用抓大放小的方式来判断差异,无法证明是新版好还是旧版好,这时候需要分解这个指标来继续分析。
## 不同用户群体有差异吗?
很多情况下,对新用户可能实验组更好,老用户对照组更好;对年轻人实验组更好,中年人对照组更好,
作为数据分析师,分析实验结论时,还要关注用户群体的差异。
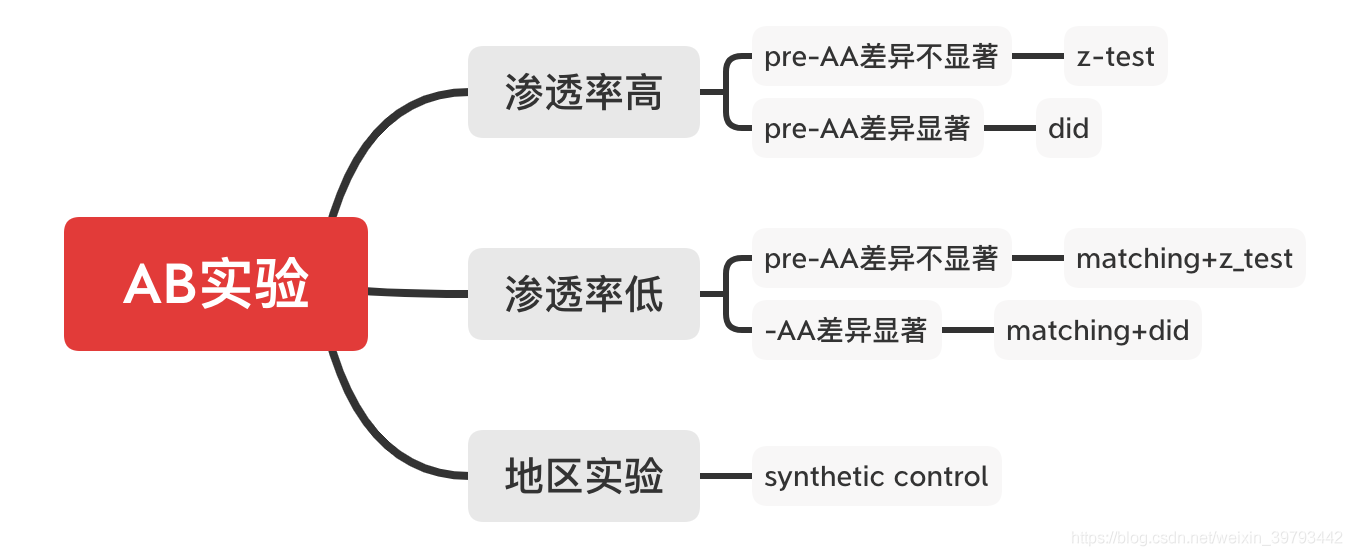
## [Matching](https://blog.csdn.net/weixin_39793442/article/details/108659971)
若最后AB结果显示两个分组无显著差异,考虑继续寻找特征相似的**细分用户进行对比分析**
# 实验结束
**实验结束后需要**:
- 反馈实验结论,包括直接效果(渗透、留存、人均时长等)、ROI
- 充分利用实验数据,进一步探索分析不同用户群体,不同场景下的差异,提出探索性分析
- 对于发现的现象,进一步提出假设,进一步实验论证
**更高级的实验:**
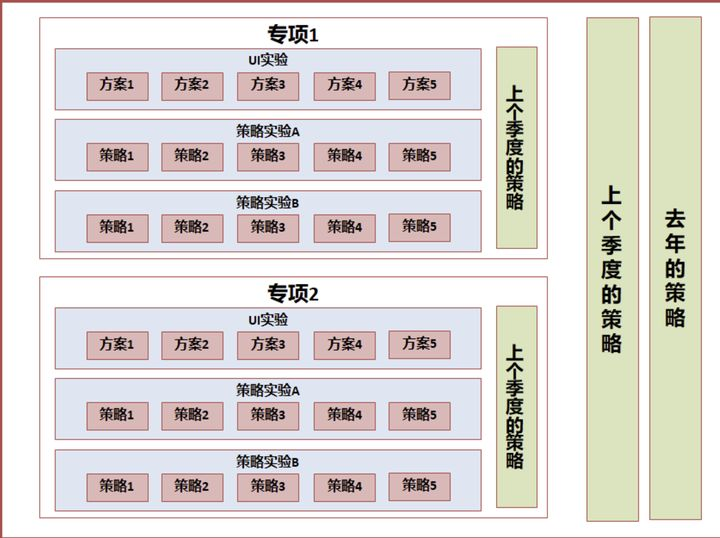
对于长线业务,可能同时有数十个实验同时进行,不但对比每项小迭代的差异,同时对比专项对大盘的贡献量、部门整体对大盘的贡献量,这样就需要运用到了实验的层域管理模型。
- 对比每个产品细节迭代的结果
- 对比每个专项在一个阶段的贡献
- 对比整个项目在一个阶段的贡献
## 多个活动交集量化的实验设计
作为数据分析师,多团队合作中,经常遇到多业务交集的问题,以我近期主要负责的春节活动为例,老板会问:
- 春节活动-明星红包子活动贡献了多少 DAU?春节活动-家乡卡子活动贡献了多少 DAU?
- 春节活动总共贡献了多少 DAU?
严谨一点,我们采用了 AB 实验的方式核算,最终可能会发现一个问题:春节活动各个子活动的贡献之和,不等于春节活动的贡献,为什么呢?
- 有的时候,活动 A 和活动 B,有着相互放大的作用,这个时候就会 1+1 > 2
- 还有的时候,活动 A 和活动 B,本质上是在做相同的事情,这个时候就会 1+1 < 2
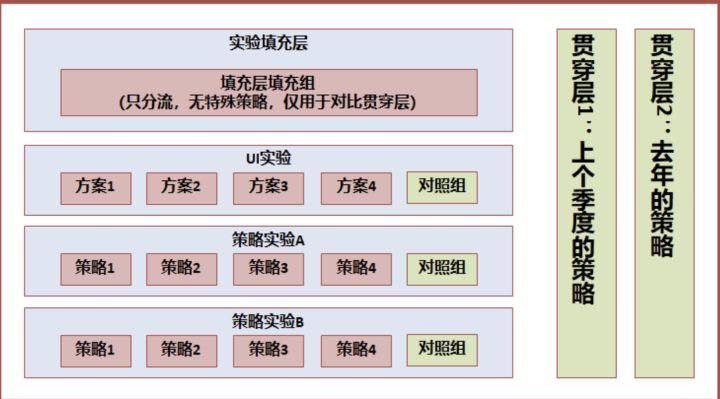
这个时候,我们准确量化春节活动的贡献,就需要一个【贯穿】所有活动的对照组,在 AB 实验系统中通俗称作**贯穿层**。

(说明:实验中,各层的流量是正交的,简单理解,例如,A 层的分流采用用户 ID 的倒数第 1 位,B 层的分流采用用户 ID 的倒数第 2 位,在用户 ID 随机的情况下,倒数第 1 位和倒数第 2 位是没有关系的,也称作相互独立,我们称作正交。当然,AB Test 实验系统真实的分流逻辑,是采用了复杂的 hash 函数、正交表,能够保证正交性。)
这样分层后,我们可以按照**如下的方式量化贡献**:
- 计算春节活动的整体贡献:实验填充层-填充层填充组 VS 贯穿层-贯穿层填充组
- 计算活动 A 的贡献:活动 A 实验层中,实验组 VS 对照组
- 计算活动 B 的贡献:活动 B 实验层中,实验组 VS 对照组
## 业务迭代的同时,如何与自身的过去比较
上面谈到了【贯穿层】的设计,贯穿层的设计其实不但可以应用在多个活动的场景,有些场景,我们的业务需要和去年或上个季度的自身对比,同时业务还不断在多个方面运用 AB Test 迭代。
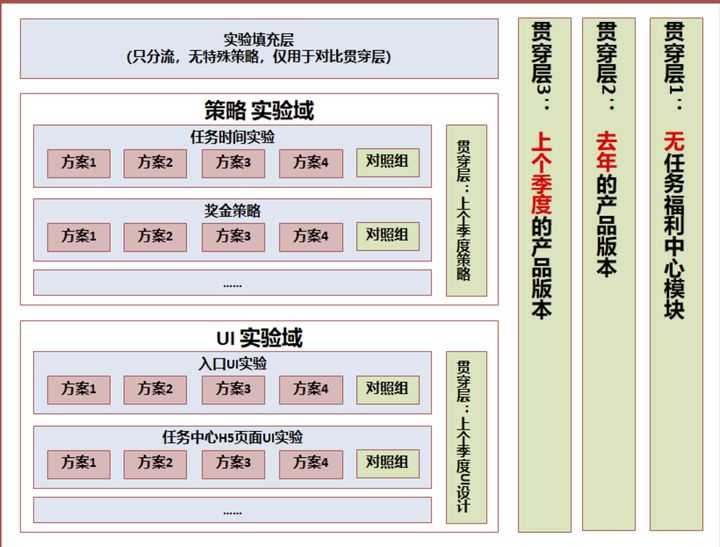
类似与上面这种层次设计,在推荐系统中较为常见,**在某一些产品或系统中,贯穿层不能够完全没有策略,那么采用去年或上个季度的策略,代表着基准值,从而量化新一个周期的增量贡献**
我们可以量化:
- 每个小迭代对整个系统的贡献:实验层中的实验组 VS 对照组
- 周期内,系统全部迭代与上个周期的比较:实验填充层 VS 贯穿层 1(或贯穿层 2)
- 同时,可以量化去年策略的自然增长或下降,以衡量旧有系统是否具有长期的适用性(作为系统设计者,更应鼓励设计具有长期适应性的系统):贯穿层 1(上个季度的策略)VS 贯穿层 2(去年的策略)
**更为复杂的实验设计**
我以我目前负责的业务,微视任务福利中心的实验设计为例,举例一个更复杂的实验系统设计,综合了上面提到的 2 个目的:
- 量化每一个实验迭代为系统带来的增量贡献
- 量化每一类迭代(如 UI 迭代、策略迭代),在一个阶段的增量贡献
- 量化系统整体在上一个周期(季度、年)的增量贡献
- 量化任务福利中心的整体 ROI(本质上,是给用户一些激励,促进用户活跃,获得更多商业化收益,所以和推荐系统不同的是,需要有完全没有任务福利中心的对照组,用户量化 ROI)
---
**转载**:
[AB测试-最佳方案测试](https://blog.csdn.net/boonya/article/details/115415123)
[数据分析|如何做一个ABtest测验](https://zhuanlan.zhihu.com/p/75762862)
[AB实验分析流程](https://blog.csdn.net/YWJ_WJY/article/details/118027814)
[数据分析系列:如何做一次ABtest?](https://zhuanlan.zhihu.com/p/165406531)
[携程机票的ABTest实践](https://zhuanlan.zhihu.com/p/25685006)