Hadoop、HDFS、Mapreduce
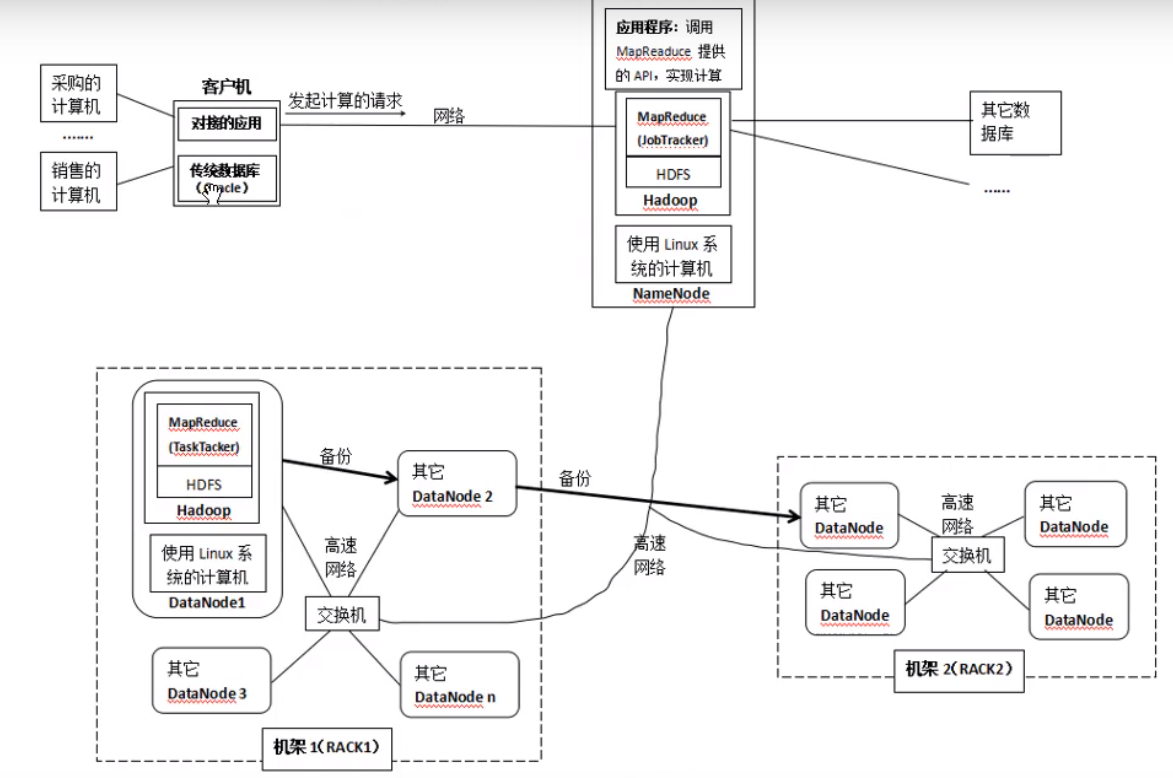
# [Hadoop安装在集群上后的结构](https://www.bilibili.com/video/BV1yW411S7pX?from=search&seid=3204228881718086816)

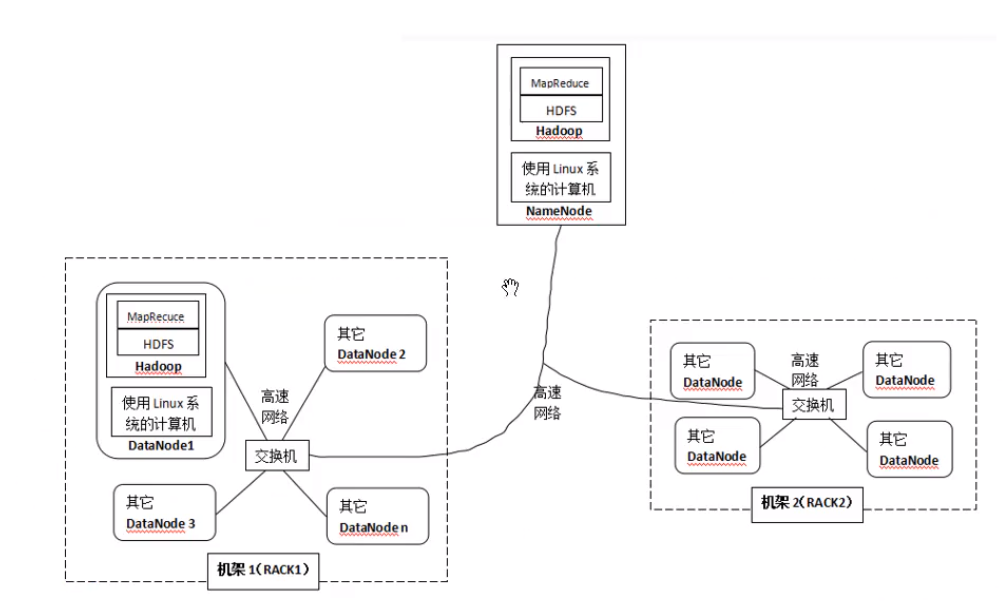
# [HDFS架构和原理](https://www.bilibili.com/video/BV1LK41157HK?from=search&seid=1500946004279972484)
# [MapReduce的大致工作原理](https://www.bilibili.com/video/BV1CW411S79e?t=919)
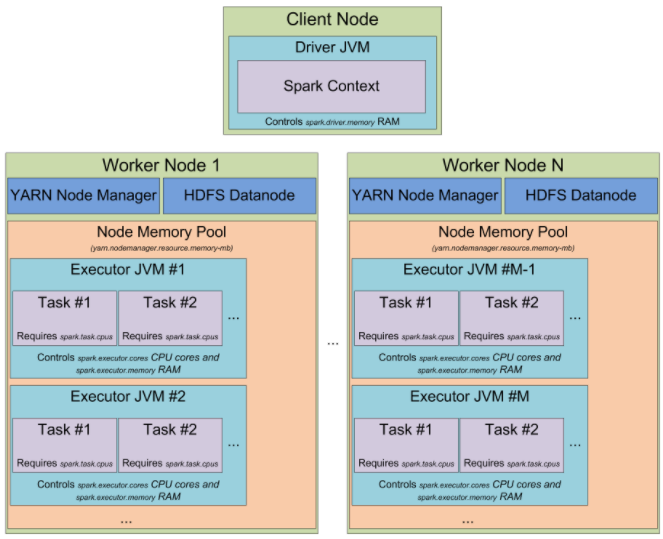
[Hadoop的JVM重用](https://blog.csdn.net/javastart/article/details/76724271)
> JVM重用技术不是指同一Job的两个或两个以上的task可以同时运行于同一JVM上,而是排队按顺序执行。
[流式计算(五)-Flink核心概念](https://www.cnblogs.com/xxbiao/p/12101216.html)
> ++09-任务插槽(task slot)和资源++
>
>每个工人(TaskManager)就是一个JVM进程(process),能通过独立线程执行一到多个子任务,子任务的可接收数量就叫任务插槽(task slot),至少得有1个。任务插槽代表TaskManager内的一组固定的资源集,一个TaskManager所有的任务插槽都会均分其控制的内存,比如有3个插槽的TaskManager ,各插槽被分配1/3其管理的内存,这样的好处是为了避免子任务间的资源竞争。但目前这里不涉及CPU资源,仅是内存隔离。
>
>通过调整任务插槽数,可以控制子任务的隔离度。比如TaskManager只有一个任务插槽,即意味着每个任务组运行在独立的JVM(可运行在容器内)中,有多个任务插槽则意味着共享JVM内TCP连接(多路复用方式)和心跳消息,可能还共享数据集和数据结构,从而减少总体负载。
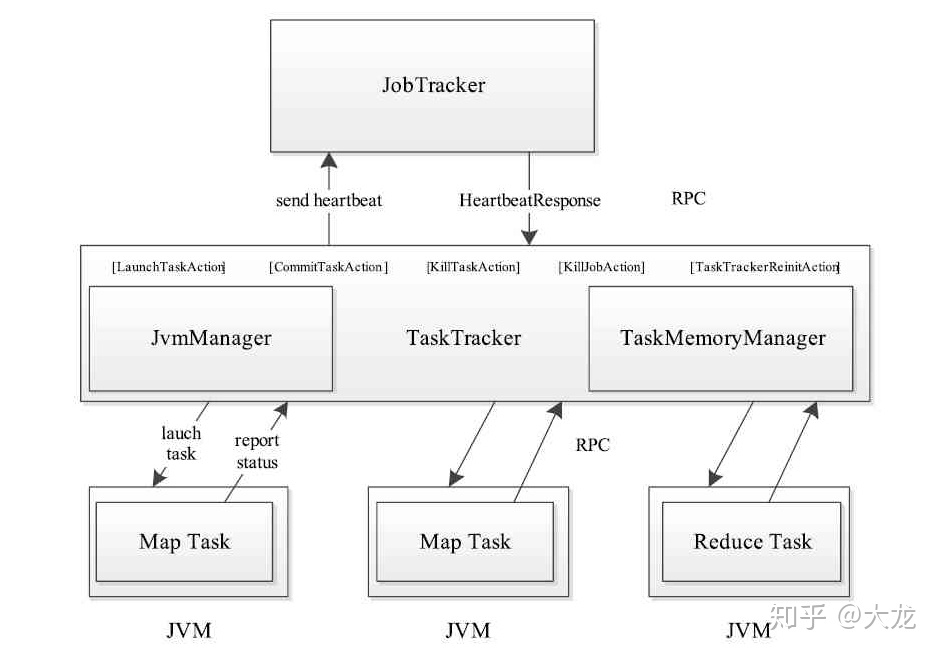
[MapReduce(4)—— TaskTracker的任务启动介绍](https://zhuanlan.zhihu.com/p/136445323)
> TaskTracker接收到新的任务之后,借助JvmManager为该任务启动一个新的JVM或者将该任务分配给已有的JVM执行。对正在运行的JVM来说,TaskTracker是一个RPC Server, 每个JVM从TaskTracker处获取需要执行的任务,并通过RPC通信来更新任务的运行信息。由于每个JVM启动都需要耗费一定的资源,所以我们需要限制启动的JVM的个数,但如果只启动一个JVM又降低了整个系统的作业吞吐。JVM的启动、杀死以及复用由JvmManager来负责。
>
>