HDFS、MapReduce、Hive、Hadoop架构
# 1、HDFS架构
HDFS是一个分布式文件系统,为Hadoop其他组件提供存储支持。
HDFS是主从架构。主HDFS命名为名称节点(NameNode),而从HDFS命名为数据节点(DataNode)。
NameNode是一个管理文件系统命名空间和调整客户端文件访问(开启、关闭、重命名及其他操作)的服务器。它将输入数据分块并且公布存储在各个数据节点上的数据。
DataNode是一个从装置,它存储分区数据集的副本并且收到请求时提供数据。它还进行块的创建和删除。
HDFS的内部机理可将文件划分为一个或多个块,这些块储存在一系列数据节点中。在一般情况下,需备份3个复件,HDFS将第一个复件保存在本地节点中,第二个保存在本地另一个节点的磁道中,第3个复件保存在其他节点的磁道中。HDFS支持大文件,它的块容量为64MB,根据需求,可以进行扩充。
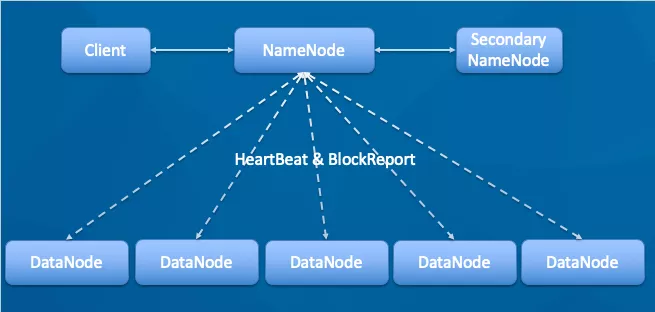
## 1.1 HDFS组件
HDFS使用主从架构进行管理,包括以下组件:
**Client**:客户端。
**名称节点(NameNode)**:这是HDFS的主干。它维护目录、文件以及管理在数据节点上的块。
**数据节点(DataNode)**:这些是被部署在每台机器上并且提供实际存储的从动装置。它们负责为客户提供读写数据的服务。
**代理主节点(Secondary NameNode)**:它负责周期性检查中断点,如果主节点突然中断,可由储存在代理主节点中的中断点镜像来代替。
## 1.2 HDFS的存储机制
HDFS存储机制,包括HDFS的写入数据过程和读取数据过程两部分
**HDFS写数据过程**
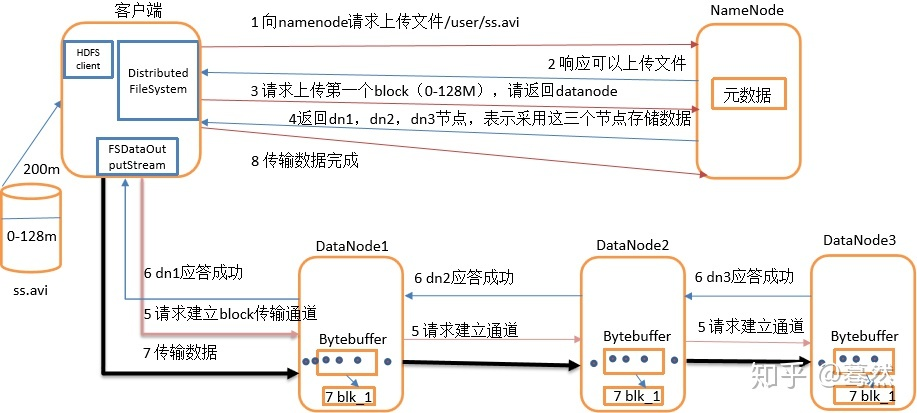
1. Client将文件切分成一个一个的Block,然后通过Distributed FileSystem模块向NameNode请求上传文件,NameNode检查目标文件是否已存在,父目录是否存在。
2. NameNode返回是否可以上传。
3. 客户端请求第一个 block上传到哪几个datanode服务器上。
4. NameNode返回3个datanode节点,分别为dn1、dn2、dn3。
5. 客户端通过FSDataOutputStream模块请求dn1上传数据,dn1收到请求会继续调用dn2,然后dn2调用dn3,将这个通信管道建立完成。
6. dn1、dn2、dn3逐级应答客户端。
7. 客户端开始往dn1上传第一个block(先从磁盘读取数据放到一个本地内存缓存),以packet为单位,dn1收到一个packet就会传给dn2,dn2传给dn3;dn1每传一个packet会放入一个应答队列等待应答。
8. 当一个block传输完成之后,客户端再次请求NameNode上传第二个block的服务器。(重复执行3-7步)。
**HDFS读数据过程**
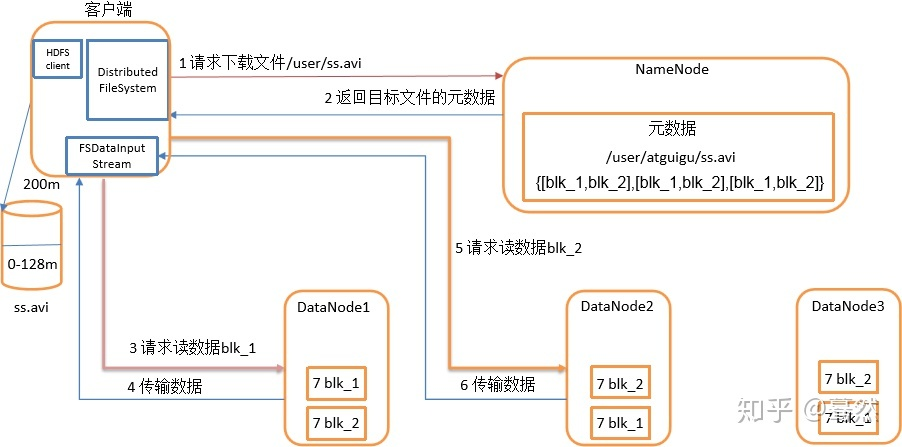
1. 客户端通过Distributed FileSystem向NameNode请求下载文件,NameNode通过查询元数据,找到文件块所在的DataNode地址。
2. 挑选一台DataNode(就近原则,然后随机)服务器,请求读取数据。
3. DataNode开始传输数据给客户端(从磁盘里面读取数据输入流,以packet为单位来做校验)。
4. 客户端以packet为单位接收,先在本地缓存,然后写入目标文件。
# 2、MapReduce 1.X 架构
MapReduce是一个分布式计算软件构架,它可以支持大数据量的分布式处理。
MapReduce也采用主从架构,典型的MapReduce 包含作业提交、作业的初始化、任务分配、任务执行、进度和状态更新,以及作业完成相关的活动,这主要是由JobTracker节点管理和TaskTracker节点执行。
客户端应用程序提交作业给JobTracker,然后在整个集群中划分输入,JobTracker再计算要处理的Map和Reduce执行单元的数量,并命令TaskTracker开始执行该作业。TaskTracker必须复制资源到本地计算机,并启动JVM对数据进行Map和Reduce操作。与此同时,TaskTracker必须周期性地发送更新信息给JobTracker,这称为心跳(heartbeat),用于帮助更新作业ID、作业状态和资源使用情况。
## 2.1 **MapReduce组件**
MapReduce是由包含以下几部分的主从架构管理的:
<font color=Blue>**JobTracker**</font>:它是MapReduce系统的主机节点,管理着集群中的作业及资源。JobTracker规划好每个Map,使TaskTracker中实际正在被处理的数据同Map尽量接近,正运行该数据节点的TaskTracker作业优先执行。
<font color=Blue>**TaskTracker**</font>:这些都是部署在每台机器上的客户机节点。它们负责由JobTracker分配的Map和Reduce作业。
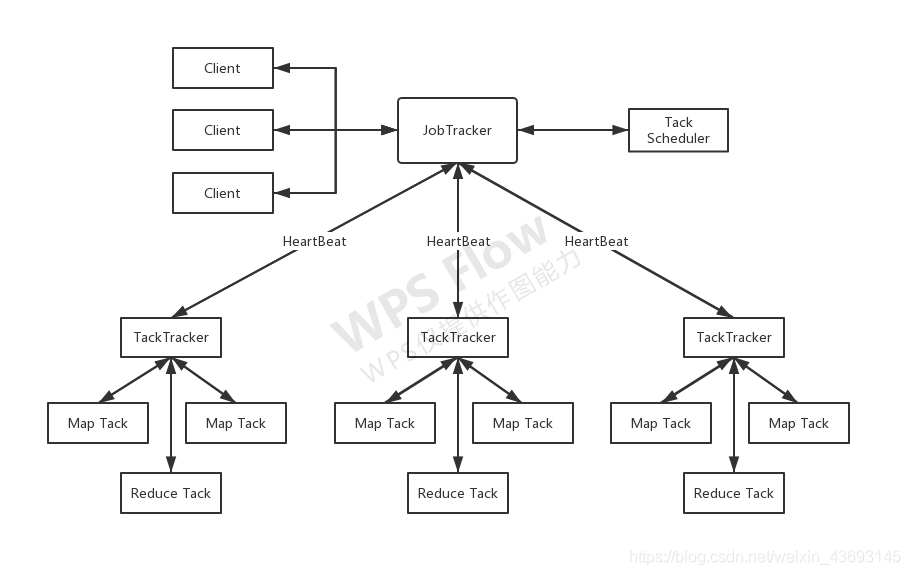
1. **Client**
用户编写的Map Reduce程序通过Client提交到Job Tracker端;同时 ,用户可以通过Client提供的一些接口查看作业运行状态。在Hadoop内部用“作业”(Job)来表示Map Reduce程序。一个Map Reduce程序可对应若干个作业,每个作业会被分解成若干个Map/Reduce任务(Task)。
2. **JobTracker**
JobTracker主要负责资源监控和作业调度。Job Tracker监控所有的TaskTracker与作业的健康状况,一旦发现失败情况后,会将相应的任务转移到其它节点;同时,Job Tracker会跟踪任务的执行进度、资源使用量等信息,并将这些信息告诉任务调度器,而调度器会在资源出现空闲时,选择合适的任务使用这些资源。在Hadoop中任务调度器是一个可插拔的模块,用户可以根据自己的需求设计相应的调度器。
3. **TaskTracker**
Task Tracker会周期性的通过HeartBeat将本届电商资源的使用情况和任务的运行进度汇报给Job Tracker,同时接受Job Tracker发送过来的命令并执行相应的操作(如启动新任务、杀死任务等)。Task Tracker使用“slot”等量划分本节点上的资源量。“slot”代表计算资源(如CPU、内存等)。一个Task获取到一个slot后才有机会运行,而Hadoop调度器的作用就是将各个Task Tracker上的空闲slot分配给Task使用。slot分为Map slot和Reduce slot两种,分别公Map Task和Reduce Task使用,Task Tracker通过slot数目限定Task的并发度。
4. **Task**
Task分为Map Task和Reduce Task两种,均由Task Tracker启动。
- **Map Task执行过程**
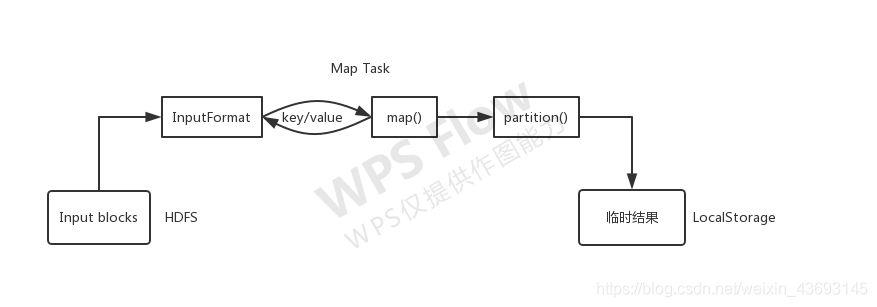
Map Task对应的源数据迭代解析成一个个key/value对,依次调用用户自定义的map()函数进行处理,最终将临时结果存放到本地磁盘上,其中临时数据被分成若干个partition,每个partition将被一个Reduce Task处理。
- **Reduce Task执行过程**
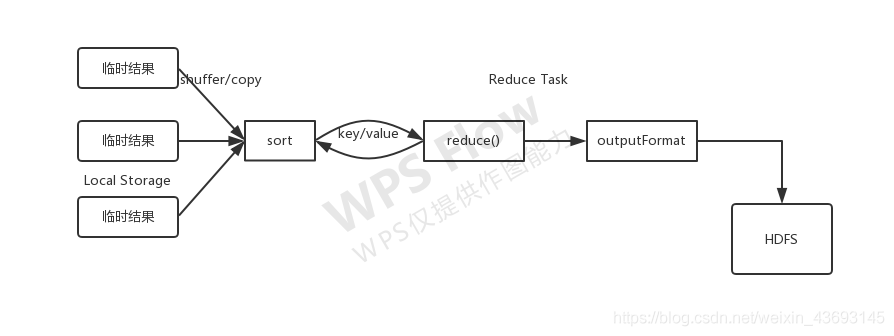
**该过程分为三个阶段:**
(1)从远程节点上读取Map Task中间结果(称为“shuffle阶段”);
(2)按照key对key/value对进行排序(称为“sort阶段”);
(3)一次读取<key,value list>,调用用户自定义的reduce()函数处理,并将最终结果存到HDFS上(称为“reduce阶段”).
# 3、通过图示了解HDFS和MapReduce 1.X架构
在下图中,NameNode和DataNode在HDFS上,JobTracker和TaskTracker在MapReduce范式中,HDFS和MapReduce主服务器和从服务器部件也包括其中。
本图包含了HDFS和MapReduce的主从组件,其中名称节点和数据节点来自HDFS,JobTracker和TaskTracker来自MapReduce。
两个示例都是由主从组件构成的,在控制MapReduce和HDFS的操作中各有分工。在该图中包括两个部分:前一个是MapReduce层,后一个是HDFS层。
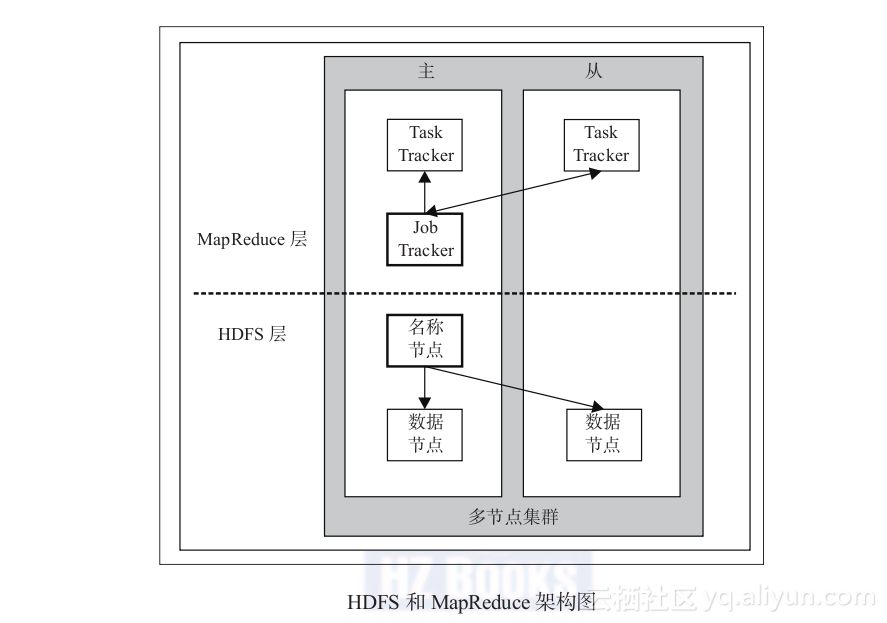
这里可能有人会混淆JobTracker、TaskTracker和DataNode、NameNode。其实JobTracker对应于NameNode,TaskTracker对应于DataNode。DataNode和NameNode是针对数据存放来而言的,JobTracker和TaskTracker是对于MapReduce执行而言的。
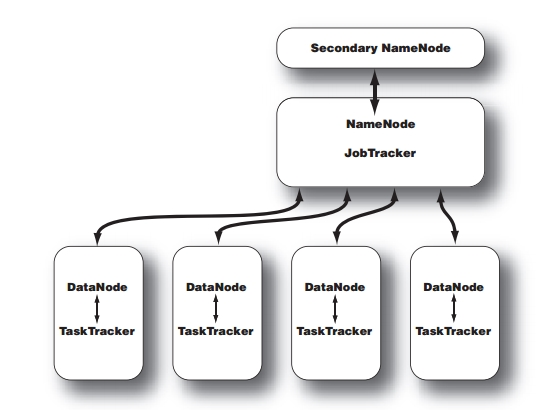
>刚好看到关于Name node/Data node和Job tracker/Task tracker的解释,一开始有点混淆,以为说Job tracker必须运行在Name node上,他们俩有依赖或者从属关系。其实不是这样的。他们间的区别在于
>
>1)Name node/Data node是HTFS层面上的东西,是服务器角色;Job tracker/Task tracker是Hadoop任务调度的一部分,是一组任务;
>
>2)Name node负责的是如何将文件分割成多个HTFS文件块,交给MapReduce处理后存储到哪些Data node上,要复制到哪些Data node,所以这一切都是存储层面上的东西;而Job tracker是服务端应用程序和Hadoop之间通信的桥梁,客户端提交数据请求,由Job tracker决定执行计划,分配给不同的Task tracker任务的执行计划,每个Task tracker在它的Data node上要执行Map和Reduce函数。Job tracker还需要处理如果Task tracker没有响应这种failure的情况,如何通过指派Task给另一个Task tracker来重启Task。Job tracker和Task tracker又是通过心跳线来报告健康情况的。所以这样看,Job tracker就是一个调度器(scheduler),调度Task tracker的执行,而Task tracker又是另一个调度器,调度自己本机上的MapReduce任务运行。这就是一种典型的主从编程结构(Master\Slave)。虽然Task tracker每个节点只有一个,但是可以通过生成多少Java虚拟机(JVM)来执行多个Map和Reduce任务。
- TaskTracker是运行在多个节点上的slaver服务。TaskTracker主动与JobTracker通信,接收作业,并负责直接执行每一个任务。 **TaskTracker 都需要运行在HDFS的DataNode上。**
>**注:MapReduce 1.x的缺点**
随着分布式系统集群的规模和其工作负荷的增长,原框架的问题逐渐浮出水面,主要的问题集中如下:
>
>- JobTracker 是 Map-reduce 的集中处理点,存在单点故障。
>- JobTracker 完成了太多的任务,造成了过多的资源消耗,当 map-reduce job 非常多的时候,会造成很大的内存开销,潜在来说,也增加了 JobTracker fail 的风险,这也是业界普遍总结出老 Hadoop 的 Map-Reduce 只能支持 4000 节点主机的上限。
>- 在 TaskTracker 端,以 map/reduce task 的数目作为资源的表示过于简单,没有考虑到 cpu/ 内存的占用情况,如果两个大内存消耗的 task 被调度到了一块,很容易出现 OOM。
>- 在 TaskTracker 端,把资源强制划分为 map task slot 和 reduce task slot, 如果当系统中只有 map task 或者只有 reduce task 的时候,会造成资源的浪。
>- 源代码层面分析的时候,会发现代码非常的难读,常常因为一个 class 做了太多的事情,代码量达 3000 多行,,造成 class 的任务不清晰,增加 bug 修复和版本维护的难度。
>- 从操作的角度来看,现在的 Hadoop MapReduce 框架在有任何重要的或者不重要的变化 ( 例如 bug 修复,性能提升和特性化 ) 时,都会强制进行系统级别的升级更新。更糟的是,它不管用户的喜好,强制让分布式集群系统的每一个用户端同时更新。这些更新会让用户为了验证他们之前的应用程序是不是适用新的 Hadoop 版本而浪费大量时间。
# 4、MapReduce 2.X / Yarn框架架构
>经典mapReduce最重要的限制主要关系到可伸缩性、资源利用和对与MapReduce不同工作负载的支持。
>
>于是Hadoop2.X将资源调度和任务调度分开了。
>
>首先客户端不变,其调用的Api以及接口大部分保持兼容,但是**原本的JobTracker和TaskTracker被ResourceManager、ApplicationMaster和NodeManager取代了。**
>
>在Yarn架构中ResourceManager以一个全局的主要后台进程的形式运行,他通常在专门的机器上运行,作为一个主核心,在各个应用程序之间仲裁可用的集群资源。承担起了MRv1的JobTracker的集群的资源管理和调度任务。
>
>ResourceManager会知道集群上有多少可用的活动节点和资源(NodeManager与RM汇报资源),协调用户提交的job应该在什么时候获取这些资源,它是唯一拥有此信息的进程。
>
>ApplicationMaster负责一个job生命周期内的所有工作,比如任务切分、任务调度、任务监控和容错等。每一个job(不是每一种)都有一个ApplicationMaster,它可以运行在ResourceManager以外的机器上。
>
>**NodeManager是Track Trackerde的一种更加普通和高效的版本**,它的功能比较专一,就是负责Container状态的维护,并向RM保持心跳。
YARN 是 Hadoop 2.0 版本以后的资源管理器,即 MapReduce 2.0,相比于 1.0 版本,架构中的各个模块分工明确,在性能和稳定性上都有所提升。YARN 负责整个集群资源的管理和调度,也就是说**所有的 MapReduce 都需要通过它来进行调度**,支持多种计算框架。
它的基本设计思想是将MRv1中的JobTracker拆分成了两个独立的服务:一个全局的资源管理器ResourceManager和每个应用程序特有的ApplicationMaster。
其中ResourceManager负责整个系统的资源管理和分配,而ApplicationMaster负责单个应用程序的管理。ApplicationMaster 承担了以前的 TaskTracker 的一些角色,ResourceManager 承担了 JobTracker 的角色。
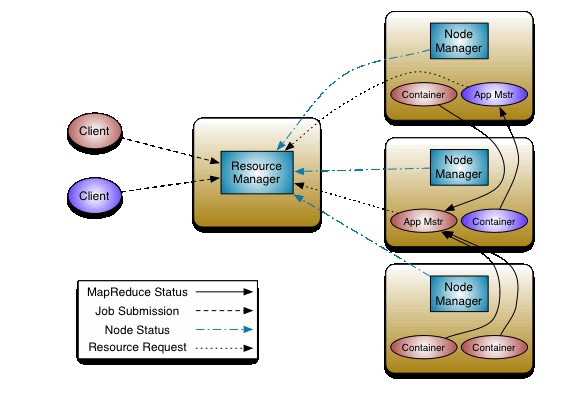
**YARN是一个资源管理、任务调度的框架**,主要包含三大模块:ResourceManager(RM)、NodeManager(NM)、ApplicationMaster(AM)。
其中,ResourceManager负责所有资源的监控、分配和管理;ApplicationMaster负责每一个具体应用程序的调度和协调;NodeManager负责每一个节点的维护。对于所有的applications,RM拥有绝对的控制权和对资源的分配权。而每个AM则会和RM协商资源,同时和NodeManager通信来执行和监控task。 几个模块之间的关系如图所示。
## 4.2 YARN 的重要概念:
1. **ResourceManager**
负责接受客户端提交的 job,分配和调度资源
启动 ApplicationMaster,判断 job 所需资源
监控 ApplicationMaster,在其失败的时候进行重启
监控 NodeManager
2. **ApplicationMaster**
为 MapReduce 类型的程序申请资源,并分配任务
负责相关数据的切分
监控任务的执行及容错
3. **NodeManager**
管理单个节点的资源,向 ResourceManager 进行汇报
接收并处理来自 ResourceManager 的命令
接收并处理来自 ApplicationMaster 的命令
4. **Container**
Container 是 YARN 中的资源抽象,它封装了某个节点上的多维度资源,如内存、CPU、磁盘、网络等,当AM向RM申请资源时,RM为AM返回的资源便是用Container表示的。YARN会为每个任务分配一个Container,且该任务只能使用该Container中描述的资源。每个Container可以根据需要运行ApplicationMaster、Map、Reduce或者任意的程序。
## 4.3 YARN应用工作流程
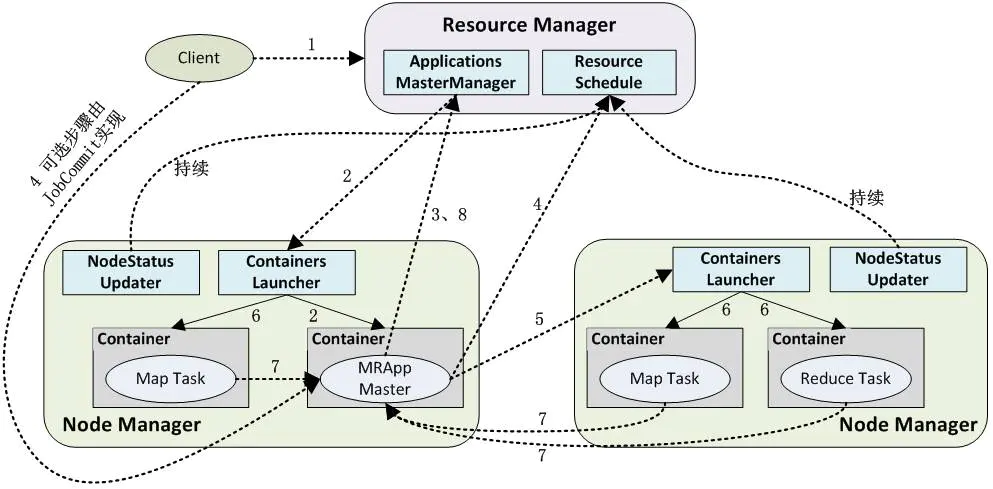
1. 用户向YARN中提交应用程序,其中包括AM程序、启动AM的命令、命令参数、用户程序等;事实上,需要准确描述运行ApplicationMaster的unix进程的所有信息。提交工作通常由YarnClient来完成。
2. RM为该应用程序分配第一个Container,并与对应的NM通信,要求它在这个Container中启动AM;
3. AM首先向RM注册,这样用户可以直接通过RM査看应用程序的运行状态,运行状态通过 AMRMClientAsync.CallbackHandler的getProgress() 方法来传递给RM。 然后它将为各个任务申请资源,并监控它的运行状态,直到运行结束,即重复步骤4〜7;
4. AM采用轮询的方式通过RPC协议向RM申请和领取资源;资源的协调通过 AMRMClientAsync异步完成,相应的处理方法封装在AMRMClientAsync.CallbackHandler中。
5. 一旦AM申请到资源后,便与对应的NM通信,要求它启动任务;通常需要指定一个ContainerLaunchContext,提供Container启动时需要的信息。
6. NM为任务设置好运行环境(包括环境变量、JAR包、二进制程序等)后,将任务启动命令写到一个脚本中,并通过运行该脚本启动任务;
7. 各个任务通过某个RPC协议向AM汇报自己的状态和进度,以让AM随时掌握各个任务的运行状态,从而可以在任务失败时重新启动任务;ApplicationMaster与NM的通信通过NMClientAsync object来完成,容器的所有事件通过NMClientAsync.CallbackHandler来处理。例如启动、状态更新、停止等。
8. 应用程序运行完成后,AM向RM注销并关闭自己。
## 4.4 YARN的优势
1. YARN的设计减小了JobTracker的资源消耗,并且让监测每一个Job子任务(tasks)状态的程序分布式化了,更安全、更优美。
2. 在新的Yarn中,ApplicationMaster是一个可变更的部分,用户可以对不同的编程模型写自己的AppMst,让更多类型的编程模型能够跑在Hadoop集群中。
3. 对于资源的表示以内存为单位,比之前以剩余slot数目更加合理。
4. MRv1中JobTracker一个很大的负担就是监控job下的tasks的运行状况,现在这个部分就扔给ApplicationMaster做了,而ResourceManager中有一个模块叫做ApplicationManager,它是监测ApplicationMaster的运行状况,如果出问题,会在其他机器上重启。
5. Container用来作为YARN的一个资源隔离组件,可以用来对资源进行调度和控制。
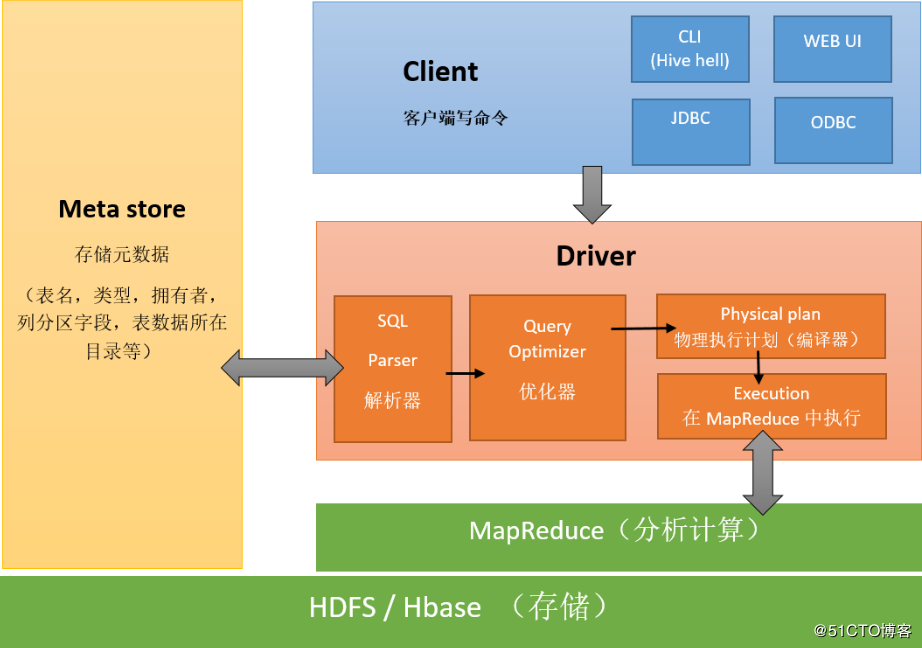
# 5、Hive 架构
# 6、Hadoop架构图
**Hadoop1.0时期架构图**
**Hadoop2.0时期架构图**
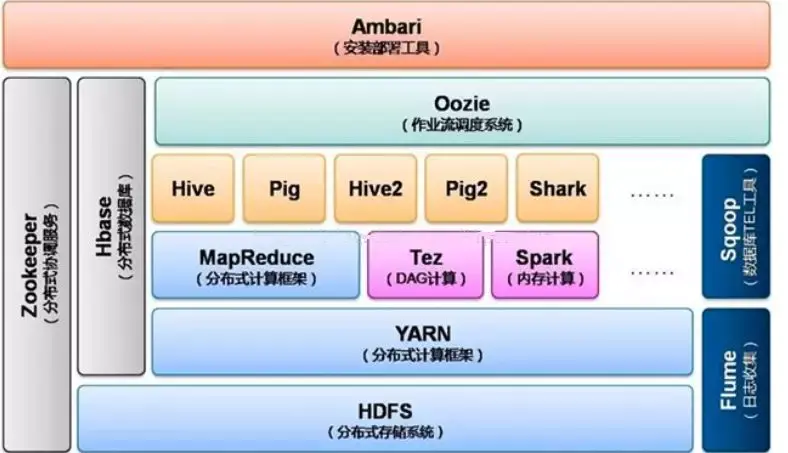
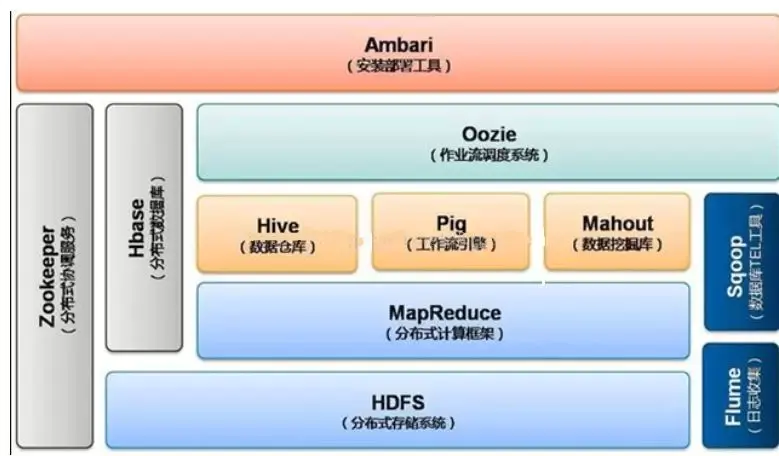
>**分析 Hadoop2.0时期架构图:**
>最底层是分布式文件系统HDFS,它是其他一些工具的基础,例如HBase。
>
>在分布式文件系统之上是资源管理与调度系统YARN。
YARN相当于一个操作系统,基于YARN可以部署离线批处理计算框架MapReduce、交互式分布式计算框架Tez,内存计算框架Spark,流式计算框架Storm等。
>
>上层可以运行Hive、Pig等数据库。Hive是一种类似于sql的分布式数据库,可以构建数据仓库。
>
>Pig是一种流数据库语言。如果需要执行多个连续的分布式计算任务,那么Oozie是理想的选择,其可以方便的执行多种任务。
>
>除此之外,Hbase可以作为分布式数据库来使用,例如构建海量图像数据的存储仓库,其查询速度很快,是面向列存储的数据库。Hadoop不能满足实时需要,HBase正可以满足。如果你需要实时访问一些数据,就把它存入HBase。它对Mrv2,Hive的支持很好,也可以作为它们的数据源或者结果存储位置
>
>ZooKeeper是分布式协调服务。
>
>Flume可以构建日志分析系统。
>
>Sqoop可以轻松将数据库中的数据导入HDFS.
具体见:[Hadoop大数据生态圈中的组件角色与关系](https://blog.csdn.net/BabyFish13/article/details/106144486)
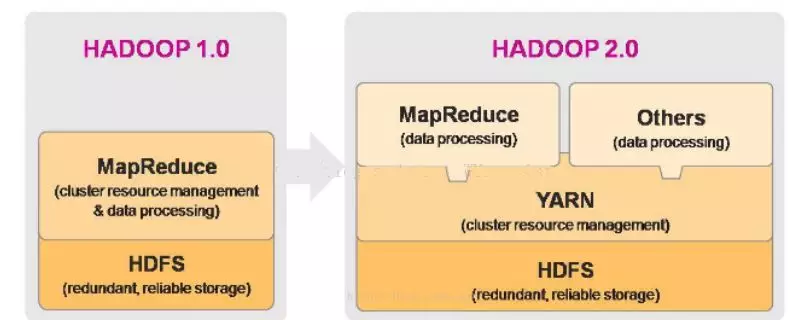
**hadoop1.0与hadoop2.0比较**
---
**转载:**
[Hadoop学习(二)——MapReduce\Yarn架构](https://juejin.cn/post/6844903779972677639)
[Hadoop 的核心 —— MapReduce & YARN(2)](https://zhuanlan.zhihu.com/p/33198500)
[MapReduce的架构组成](https://blog.csdn.net/u010176083/article/details/53269317)
[大数据Hadoop面试题(二)——HDFS](https://zhuanlan.zhihu.com/p/97711717)
[《R与Hadoop大数据分析实战》一1.6 HDFS和MapReduce架构](https://developer.aliyun.com/article/119035)
[Hadoop生态系统架构](https://juejin.cn/post/6844903599474999303)